以下てくいの!クソザコ担当、証拠の執筆記事です。暖かい目でご笑覧下さい。
本記事は、N2C2(Neural Network Console Challenge)に、てくいの!チームで参加しました、という内容です。
目次
N2C2( Neural Network Console Challenge )とは?
2020年3月4日から3月27日まで開催されている(3月25日現在)、企業データを用いてディープラーニングに挑むSonyとレッジが企画するAI開発コンテストを指します。
https://nnc-challenge.com/ (公式ホームページ)
本コンテストは、
「 Neural Network Consoleを用いてPIXTAの写真素材を画像分類する 」が大きなテーマとして挙げられています。
私たち参加者は、
①『人物画像をNNCで学習させ新しいオノマトペ(擬音語/擬声語/擬態語)の画像カテゴリ分類を作り出す』
例)ニコニコ/バチバチ/ゴリゴリ
②『画像内人物をNNCで学習させ画角/焦点距離による画像分類を作り出す』例)正面向き/バストアップ/全身/背面
③『NNCで画像を学習し人の感情によって分類』
例)嬉しい/悲しい/恥ずかしい
④上記以外のチャレンジテーマを自由に設定しての応募も可
※ただし画像分類のテーマに限る
この4つ(?)のテーマに沿って、Pixtaから提供された10000枚の画像を使用して画像分類し、運営に提出することが求められています。平たく言うと、参加者みんなでどれだけ面白いテーマで精度の高い画像分類が出来るか競争しよう!ということです。
背景
私は、③ 『NNCで画像を学習し人の感情によって分類』 のテーマを選択しました。(④にしたかったのですが、何も思いつかなかった)
手法として、てくいの!チームで分担して画像のディレクトリ分け・ラベル付けしようという提案は見事振られてしまったので、10000枚の画像をラベリングするところから始めました。
ランダムサンプリングしてラベリングする画像絞れば良かったのでは?という意見や考えには気付かない振りをしておきます。ブログを書いている途中で気付きました。切ない。
( ˘ω˘).oO (10000枚もある画像のラベル付け面倒…。画像のラベル付け…?Google Vision API…?)
ということで、私はGoogle Vision APIを使用して画像にラベル付けを行い、そのラベル(単語)を人間の感情は全27種類あるそうなので、その27種類に分類することを思いつきました。
https://www.pnas.org/content/early/2017/08/30/1702247114
以上リンク:人間の感情の27種類のソース
敬服・崇拝・称賛・娯楽・焦慮・畏敬・当惑・飽きる・冷静・困惑・渇望・嫌悪・苦しみの共感・夢中・嫉妬・興奮・恐れ・痛恨・面白さ・喜び・懐旧・ロマンチック・悲しみ・好感・性欲・同情・満足
計:27種類
Google Vision APIのラベル付けに基づいて感情分類しよう!
手法概略
①Google Vision APIで画像のラベリングを行う
②ラベルに基づいてラベル名のディレクトリ作成
③上記手順を10000枚分繰り返す
④27種類の感情ディレクトリにラベル名のディレクトリを
『手動で』割り振る
※割り振る時、ディレクトリの中身が一枚しかないもの(ex. karate, baseball-gloves)はノイズになりそうなので除外した
⑤1000件~2500件の画像を持つ感情ディレクトリに絞って画像分類を行う
使用した環境等
・Google Vision API
・Google Cloud Shell
・Neural Network Console(Windows版)
・Neural Network Console(Cloud版)
(Move content up and Zap … ディレクトリ整理でお世話になりました)
手法詳細
①Google Vision APIで画像のラベリングを行う
②ラベルに基づいてラベル名のディレクトリ作成
③上記手順を10000枚分繰り返す
作成・使用したプログラム
# GetImageMakeFile.py
# -*- coding: utf-8 -*-
import requests
import json
import base64
import config
import os
import sys
import shutil
KEY = config.API_KEY
url = 'https://vision.googleapis.com/v1/images:annotate?key='
API_url = url + KEY
# 何枚目の画像を実行してるか視覚的に分かりやすいようにカウント
counter = 0
# ディレクトリの中身を取得
files = os.listdir('/home/user_name/hogehoge')
# 取得したディレクトリの数だけ以下を実行する
for file in files:
counter = counter+1
# 画像の読み込みを行う
img_file_path = '画像が含まれているディレクトリ名/' + file
img = open(img_file_path, 'rb')
img_byte = img.read()
img_content = base64.b64encode(img_byte)
# リクエストBody作成
req_body = json.dumps({
'requests': [{
'image': {
'content': img_content
},
'features': [{
'type': 'LABEL_DETECTION'
}]
}]
})
# 現在ラベル付けを実行しているファイル名と何番目のファイルか表示
print "\n"
print file
print counter
# リクエスト
res = requests.post(API_url, data=req_body)
res_json = res.json()
labels = res_json['responses'][0]['labelAnnotations']
# 雑なエラー対策、時間があれば直す
if labels == "":
print "\n"
# 出力されたラベルの分だけ
for value in labels:
print value['description']
# ディレクトリ作成+画像の絶対パス移動
os.renames("/home/user_name/hogehoge" + file,
"/home/shoko_naka/labels/" + value['description'] + "/" + file)
# 移動した画像を元の/home/user_name/hogehogeディレクトリにコピー
shutil.copy("/home/user_name/hogehoge" + value['description'] +
"/" + file, "/home/user_name/hogehoge" + file)
# 1画像ファイルの全ラベル分ファイルを作ったら
# /home/user_name/hogehogeディレクトリから削除
os.remove("/home/user_name/hogehoge" + file)# config.py
# Google Cloud Platformプロジェクトで発行されるAPIキー
API_KEY = "****************************************"プログラムもっと綺麗に書ける気がする…(妥協)
以上の2ファイルをGoogle Cloud Shellで実行すると、
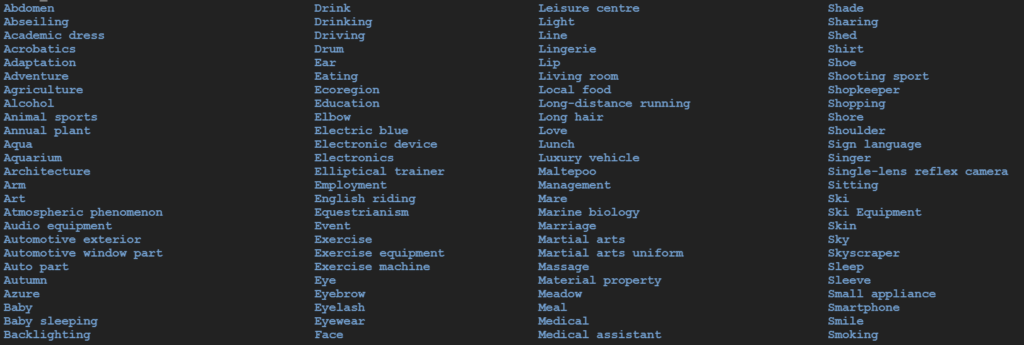
のように、ラベル名がそのままディレクトリ名として無数のファイルが生成されます。
※環境次第だとは思われますが、容量をかなり圧迫するので注意
弊環境ではメモリが足りませんとのエラーに苦しんだため
吐き出したディレクトリをZipに固めて容量の削減をしました。
④27種類の感情ディレクトリにラベル名のディレクトリを
『手動で』割り振る
※割り振る時、ディレクトリの中身が一枚しかないもの(ex. karate, baseball-gloves)はノイズになりそうなので除外した
この手順こそ何とかなったのではないかと思いますが、超個人的見解から、ラベル名がついたディレクトリを感情の名前が付いたディレクトリに分類しました。ディレクトリの中にディレクトリが…という悩みを、Move content up and Zapが一瞬で解決してくれました。一つ上の階層のディレクトリに下の階層の画像ファイルを移動し、移動して空になったディレクトリを削除してくれます。非常に便利です。
⑤1000件~2500件の画像を持つ感情ディレクトリに絞って画像分類を行う
上記条件に絞って残った感情は、
畏敬:Awe 2138件
渇望:Craving 1377件
興奮:Excitement 2176件
敬服:Respect 1559件
焦慮:Anxiety 1137件
賞賛:Praise 1791件
の6つでした。
補足(今回使用しなかった感情一覧)
恐れ:67件
懐旧:3829件
喜び:3092件
嫌悪:13件
娯楽:2577件
好感:4897件
崇拝:123件
性欲:3346件
痛恨:67件
当惑:4件
同情:297件
悲しみ:376件
飽きる:677件
満足:5032件
夢中:3082件
面白さ:3626件
冷静:3606件
嫉妬:116件
困惑:6件
苦しみの共感:695件
(ごはん系のラベルディレクトリを「満足」に入れたら凄いことになった)
ここからやっとNNC(Neural Network Console)の出番です。
始めに、ディレクトリ分けしたフォルダ(labels_jp)を参照し、Windows版のNNCを使ってデータセットを作成しました。
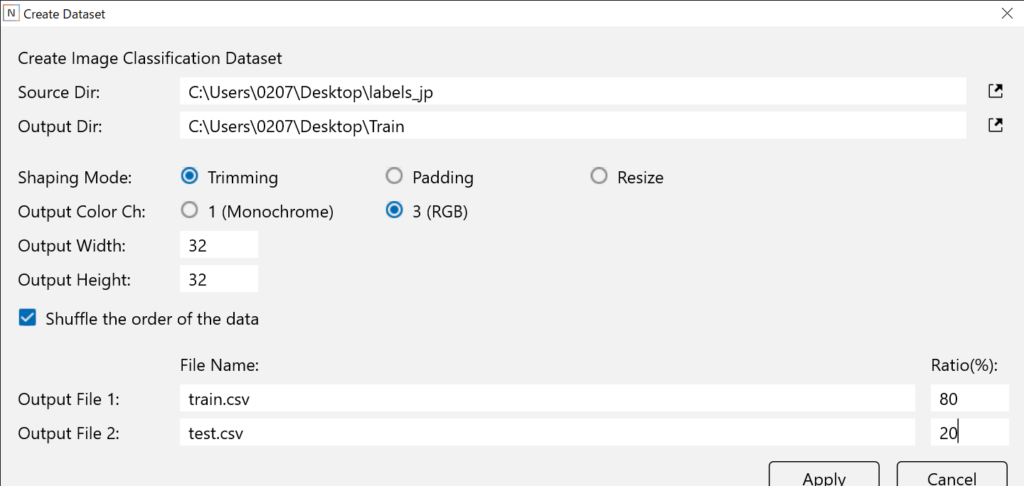
以下写真のようにtrain.csvとtest.csvが作成されます。右に見切れている、Upload Datasetからクラウド版NNCにデータセットをアップロードします。
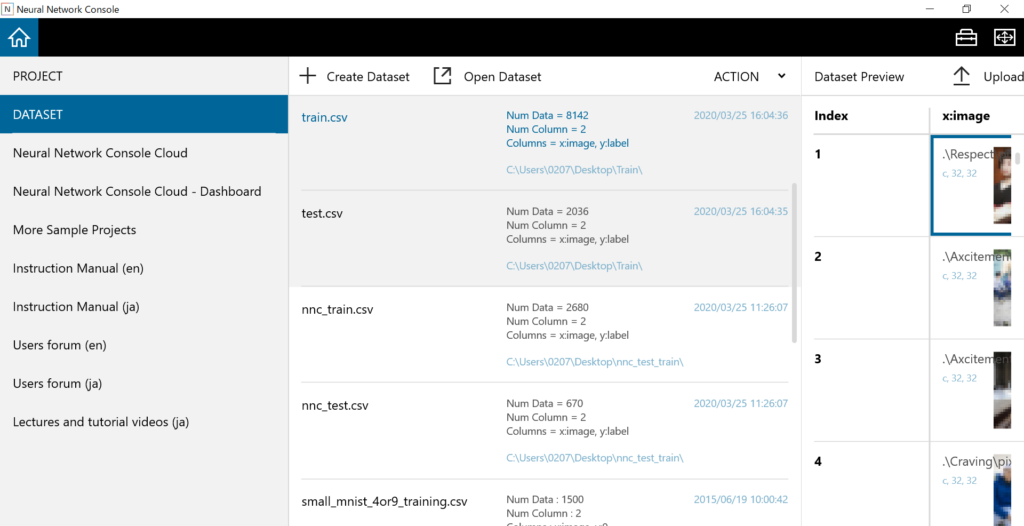
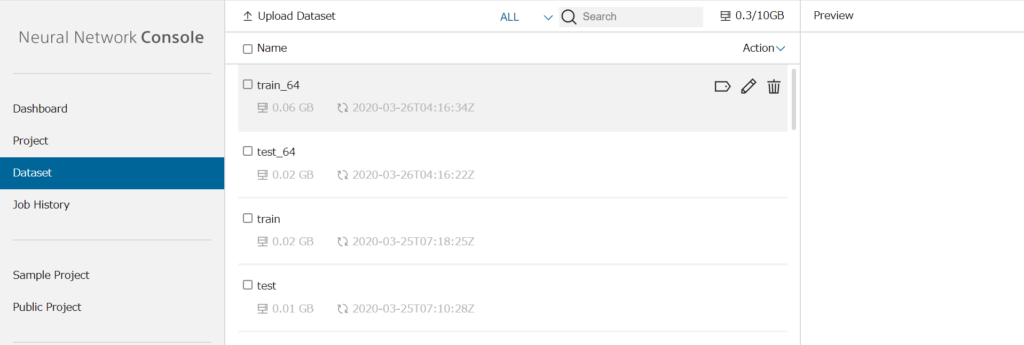
以下写真(クラウド版NNC)の、Upload Datasetを押下すると、キーが表示されるので、それをコピーして、Windows版NNCのUpload Datasetを押下すると表示されるToken:欄にペーストします。その後、Uploadを押下するとクラウド版NNCのDatasetタブにデータがアップロードされます。以下写真train, testのように表示されます。
ここから、新しいプロジェクトを作成していきます。NNCのホーム画面のProjectタブの+New Projectボタンから、新しいプロジェクトが作成出来ます。
以下写真では、上からNNCC、NNCC_64、NNCC_2_testというプロジェクトを私が作成していることが確認できます。ネーミングセンスが皆無なのがバレてしまいましたね。
新しいプロジェクトのEdit画面が以下の写真の通り表示されます。このEdit画面でモデルの追加、削除、編集を行います。
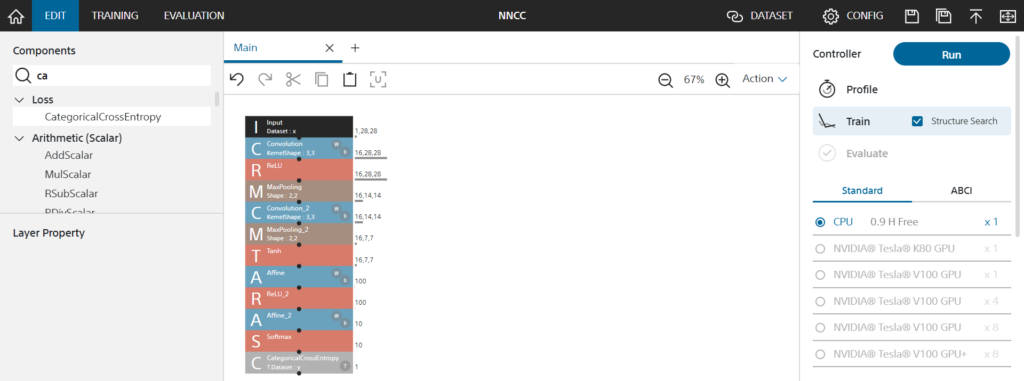
以下のようにざっくりモデルをドラッグアンドドロップして右上のRunを押し…
( ˘ω˘ ).oO (え?Error in CONFIG?バッチサイズは弄った記憶はないし…?)
確かにバッチサイズもCONFIGもモデルも弄っていませんが、DATASETも弄っていないのです。
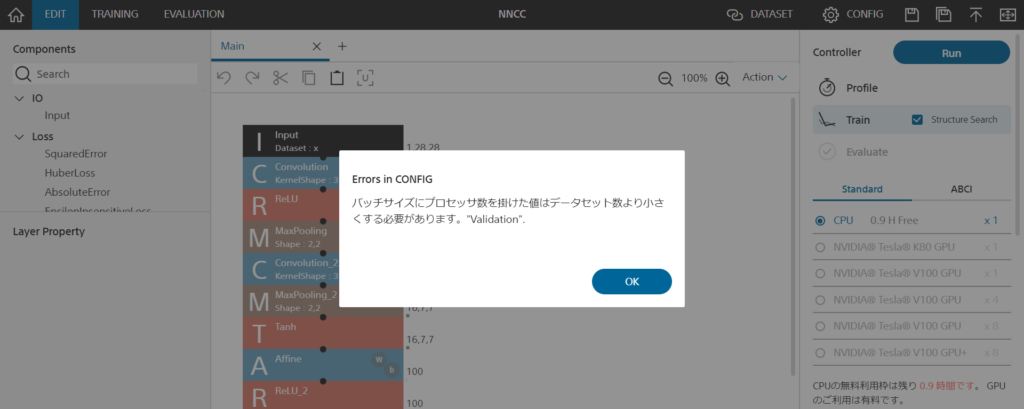
以下、真っ新で綺麗なDatasetですね。教師データもテストデータも無いならそりゃあErrorも出ます。上部のLink Dataset [Not Set]部分を押下して、折角作成してアップロードしたDatasetをtrain, Validationと紐付けましょう。
(名前は変更できるのでこの名前の通りとは限らない)
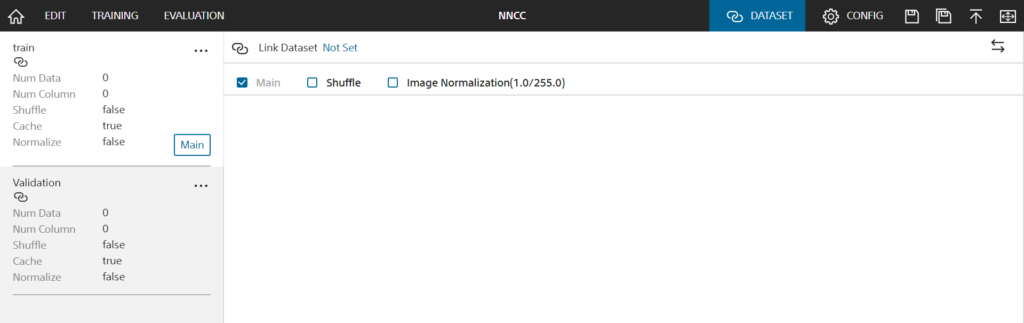
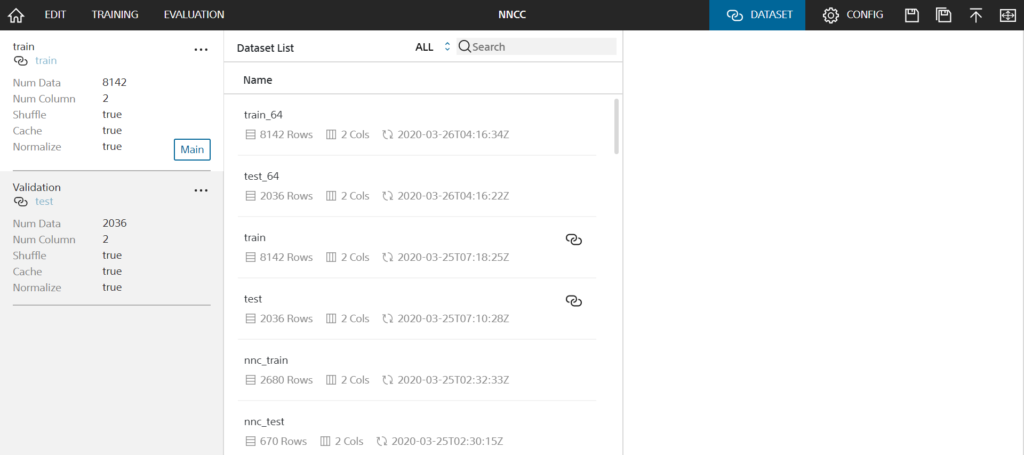
Dataset Listに、アップロードしたデータセット一覧が表示されます。そこから、鎖のようなアイコンをtrain, validationタブでそれぞれクリックし、紐付けます。これで、事前準備はばっちりのはずです!気を取り直して Edit画面から Runしてみ…
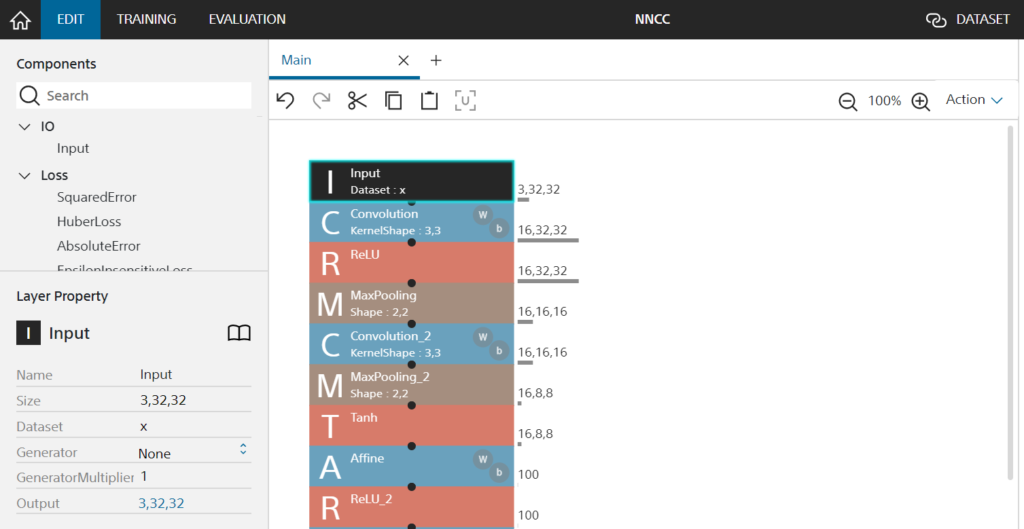
(`・ω・´).oO(待て待て、InputのSizeってデフォルトの【1,28,28】でいいんだっけ?)
今回、私は
Output Color Ch : RGB (3)
Output Width : 32
Output Height : 32
でデータセットを作成しています。
なので、InputカラムのSizeを 【1,28,28】 ->【3,32,32】に編集します。この辺りからのモデルの編集は個々のセンスが問われそうです!(丸投げとも言う)
Runしてから40分くらい経ったものが結果になります。ネタバレしてしまうと、私が作成したプロジェクトの精度はまだまだでした。
結果
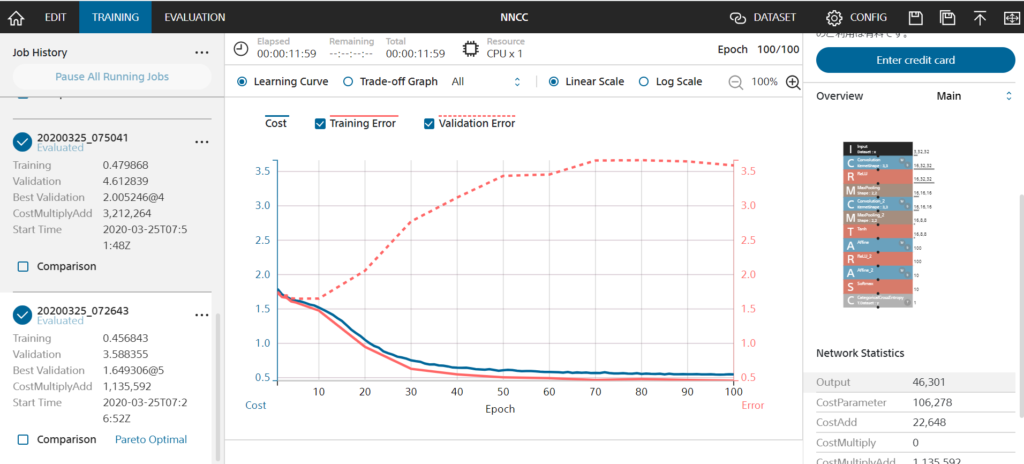
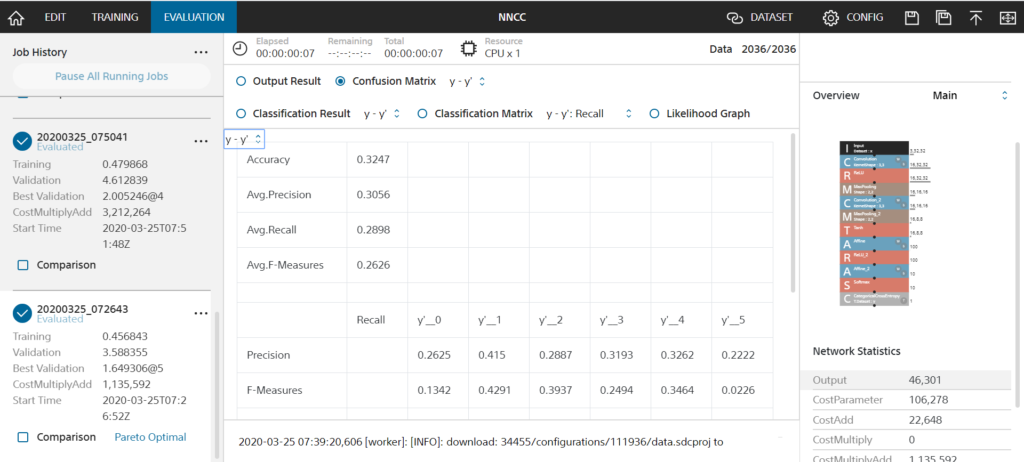
Accuracy:0.3247…(´・ω・`)
単純計算で1/6=0.166…なので精度は倍?
ごく一般的なCNN(畳み込みニューラルネットワーク)モデルを作成したはず…?因みにもっと複雑なモデルも作成したのですが、Accuracy:0.3173と同じような結果になりました。(以下写真2枚) 以下色々考察と理由を考えます。
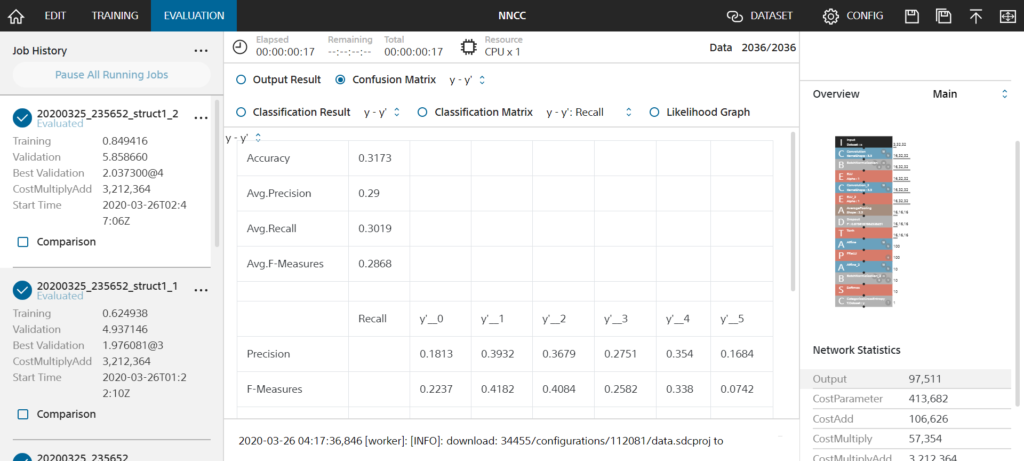
考察
使用した画像ファイルの分け方が甘いため、この程度の精度しか出なかったことが考えられる。というかこの理由が大きすぎる気がします。(同一ファイルで違うラベルが付いているなど)
また、最後は自分の直感を頼ってフォルダ分けしたため、画像ごとの類似度がごく低いものを同一ラベルにしているのかも知れません。(ラベルで出力された英単語の誤訳をしている気もしなくはない)
NNCCは3/31で終了してしまいますが、NNCはこれからも使いたいと思っているので、機械学習モデル自体の理解と元データのクリーニングをもっと頑張ります!