こんにちは、@tsum_tsumです。本記事が初投稿になります!今後、様々な記事を紹介できればと思っていますので、よろしくお願いします!
本記事では、外観検査AIモデル PatchCore を紹介します。最初に、PatchCore の特徴や実際のアルゴリズムを簡単に説明し、実際のAIモデル学習の結果も記載します。最後の部分では、アルゴリズムの理論的な説明に入るので、少し難しくなるかもしれませんが、最後まで読んでもらえると嬉しいです!
目次
そもそも外観検査とは?
外観検査とは、部品や製品の表面を検査することです。この検査は製造業を含む多くの工場で行われており、傷・凹み・歪み・異物・汚れなどの有無を確認します。検査された部品や製品は、業界や企業内で定められた基準に準拠しているかどうかが評価されます。従来の検査方法は目視に依存していましたが、以下のようなデメリットがあることが問題でした。
目視による外観検査のデメリット
- 正常・異常判定の評価基準のばらつき
- ベテラン作業員など、その製品の正常・異常判定に精通している人が必要であり、属人化することがある。
- ヒューマンエラー
- 見逃しや長時間の作業による集中力の低下によって、異常な製品が見逃されてしまう。
- 人件費等のコストの増大
機械学習の手法は様々ですが、教師あり学習と教師なし学習の2種類に分類されます。教師あり学習とは、学習データに正解を与えた状態で学習させる手法です。一方、教師なし学習とは学習データに正解を与えずに学習させる手法です。従来の外観検査の自動化では主に教師あり学習が使われていましたが、その手法には以下のようなデメリットがあります。
教師あり学習による外観検査のデメリット
- 正常な画像、異常な画像に正解(ラベル)を与える必要がある
- 画像1枚ごとにラベル付けが必要であり、作業コストがかかってしまう。
- 多くの異常画像が必要である
- 実際の製造業の現場では、不良品はめったに発生しないことから画像を集めることが難しい。
- 過去にラベル付けしていない異常画像を判定できない
- 傷と凹みというラベル付けをしたとしても、実際の運用場面で歪みの異常が発生した場合、正しいラベル付けができない。
そこで、近年では教師なし学習を用いた外観検査アルゴリズムが開発されています。今回紹介する PatchCore も教師なし学習アルゴリズムの1つです。
PatchCoreの特徴
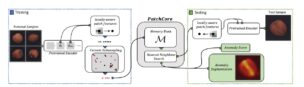
PatchCoreは、過去の教師なし学習の外観検査モデル SPADE1 や PaDiM2 を踏襲した新しいアルゴリズムです。2022年にCVPR20223で採択され、MVTecAD Dataset4 で外観検査におけるSOTA5を達成しました。
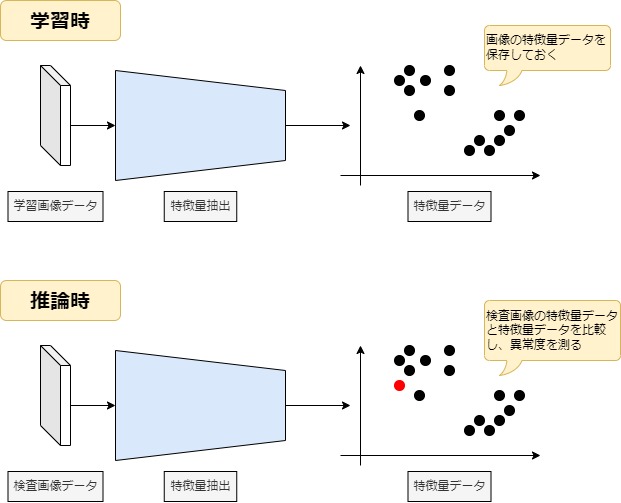
PatchCore では学習データの特徴量を保存しておき、推論時に学習時に保存しておいた特徴量と比較することで、各部品画像の異常度を測る手法を用いています。
また、上図の特徴量抽出の部分には、深層学習の学習済みモデルが使われています。この学習済みモデルは、特徴量の計算のみに使用されるため、追加学習やファインチューニングは必要ありません。そのため、勾配計算などが不要になる点も大きな特徴の1つになっています。
次に、PatchCore の大まかなアルゴリズムについて説明していきます。
アルゴリズム(学習時)
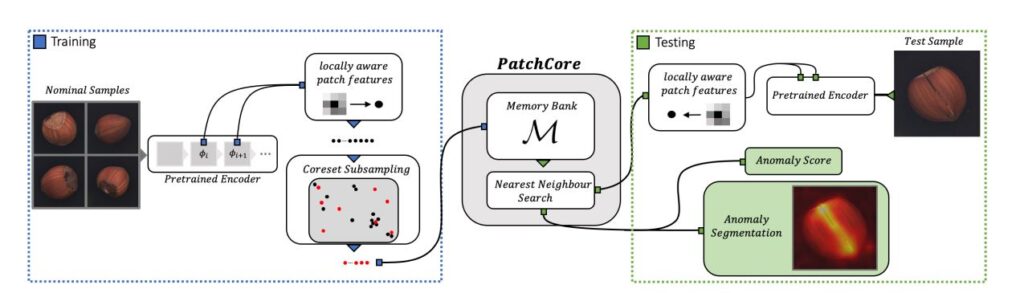
PatchCoreの学習手順は大きく2つに分けられます。
特徴量抽出
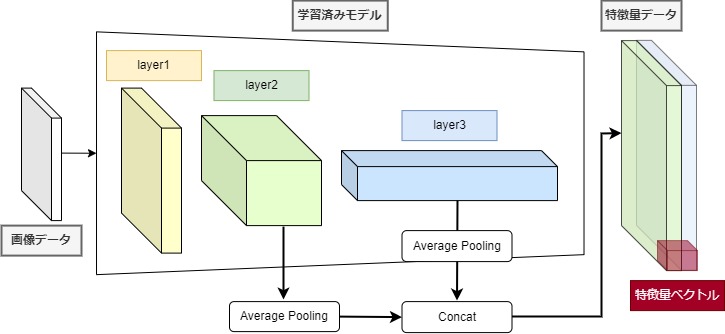
学習データと学習済みモデル6を用いて、中間層の特徴量を抽出します。このとき、複数の中間層の値を用いることで、画像の位置情報を含めた正常・異常の判定が可能になります。これによって、画像データの製品そのものの正常・異常だけでなく、異常箇所も同時に特定することができるようになります。
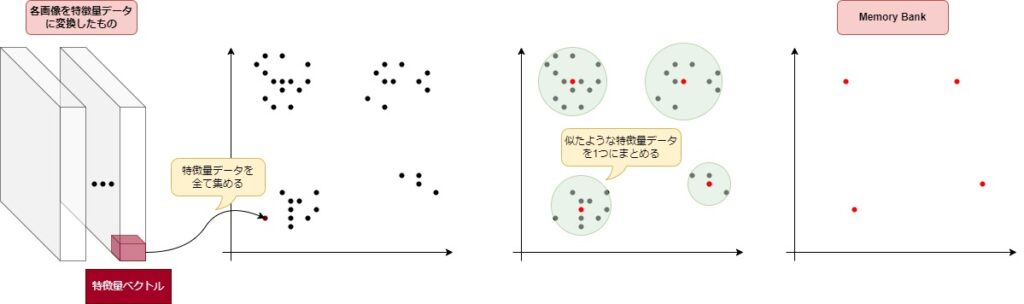
新しい特徴量集合の作成
上記の計算で得られた全ての画像の特徴量データは1つにまとめられます。しかし、学習する画像データが多ければ多いほど、特徴量データの数も増えてしまい、推論時にはメモリ使用量が増えたり、時間がかかるといったのデメリットが生じます。
そこで、特徴量データの量を適切に減らすために、貪欲法7という方法を用いて似た特徴量データを1つにまとめます。残った特徴量データの集合は Memory Bank と呼ばれ、PatchCore における学習データになります。
アルゴリズム(推論時)
上記の方法によって、Memory Bank と呼ばれる特徴量データの集合が作成されました。これを用いて推論する、PatchCore では以下の手順が進められます。
特徴量抽出
アルゴリズム(学習時)と同じように計算することによって、特徴量を抽出します。
特徴量と Memory Bank との距離計算
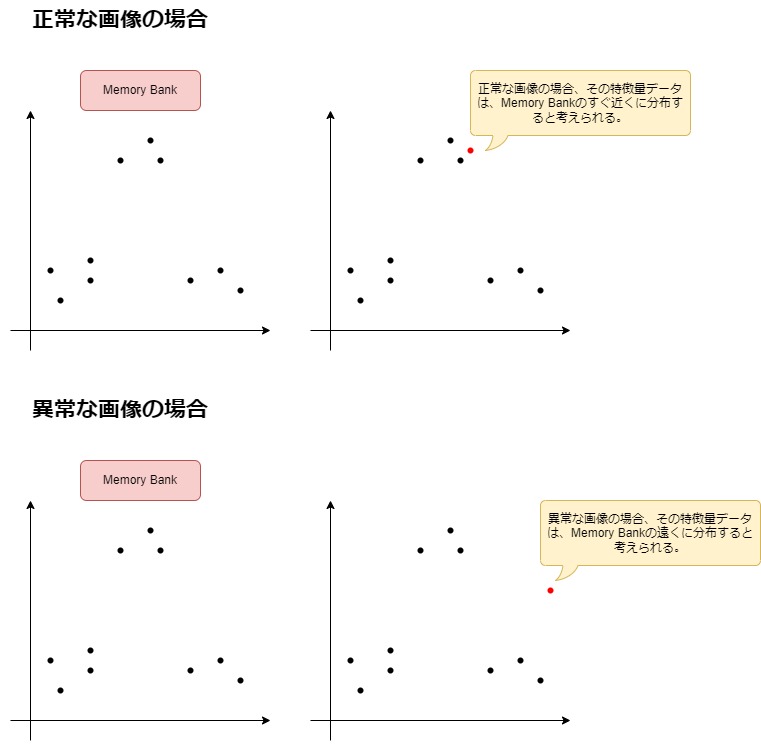
Memory Bank の各特徴量と推論したい画像の特徴量を比較し、推論したい画像の特徴量から最も近い Memory Bank の特徴量までの距離を計算します。この計算には厳密にはさらに複雑な手法が必要ですが、補足に記載しておきます。Memory Bank にはあらかじめ正常な画像の特徴量データが保存されています。このとき、下記のようなことが分かります。
- 推論したい画像が正常な場合
学習した画像データと類似しているはずなので、同じような特徴量データが生成されるはずです。よって、推論したい画像の特徴量データは、Memory Bank から近い位置に生成されると考えられます。 - 推論したい画像が異常な場合
学習データに存在しない特徴量が抽出されるはずです。よって、推論したい画像の特徴量データは、Memory Bank の特徴量データから遠い位置に生成されると考えられます。
以上が PatchCore のアルゴリズムについての説明でした。それでは実際に、PatchCore の実装を使った学習および推論結果を確認していきましょう。
実行環境
PC周りの環境
環境は以下の通りです。
- Windows10 Pro 22H2 (64bit)
- WSL2(Ubuntu-20.04.6 LTS)
- Docker Desktop for Windows 4.16.3
- NVIDIA グラフィックボードとドライバ
- GeForce RTX 3060
- NVIDIA グラフィックスドライバー 528.79
ハイパーパラメータ
PatchCoreを実行する場合、パラメータの設定が必要になります。実際の運用環境では、設定によって精度や推論時間が変化するため、環境によって最適なパラメータを設定する必要があります。本検証では、下記のパラメータで実行しています。
- 使用した学習済みモデル:WideResnet-50×2
- Memory Bank の取得割合:25%
- 取得する近傍数:9個
ソースコード
PatchCoreのソースコードはこちらを一部改変の上、使用しています。
使用画像データ
画像はこちらで撮影した綿棒を使用しています。一部の画像を添付しておりますので、確認してみてください。
- データ加工
画像データをどのように加工するのかも PatchCore におけるパラメータの1つとされています。今回は下記のようなパラメータで実行しています。 - 学習画像データ
- 良品の綿棒×16枚(縦320×横320)




- 良品の綿棒×16枚(縦320×横320)
- 推論データ
- 良品の綿棒×8枚(縦320×横320)


- 不良品の綿棒×20枚(縦320×横320)
異物を取り付ける、折る、色付けなど様々な異常を作成しています。







- 良品の綿棒×8枚(縦320×横320)
実行結果
上記の推論用の画像データ(良品×8枚、不良品×20枚)を用いた結果は、下記の通りです。
- 全体的な結果
1枚のみ不良品画像を良品と判断したが、概ね正しい識別ができていることが分かります。なお、True label の 0 は「良品の綿棒の画像」、1 は「不良品の綿棒の画像」を表しています。またPredicted label の 0 は「良品である判定した画像」、1 は「不良品であると判定した画像」を表しています。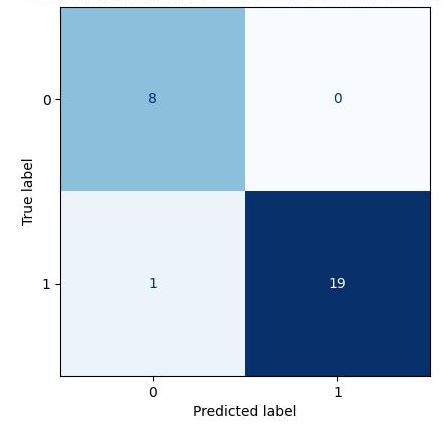
- ヒートマップ
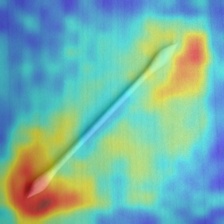
- 良品画像
下図のように綿棒の綿部分が赤くなっており、異常箇所と判定されているように見えます。これは全ピクセルの異常値の相対評価によってピクセル表示しているためです。後述のように、閾値を適切に設定することで、異常箇所の表示・非表示を制御できます。
- 不良品画像
異物、汚れ、欠けなど、あらゆる不良箇所に対応できていることが分かる。
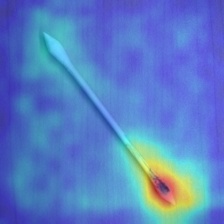


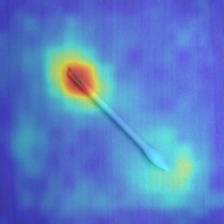
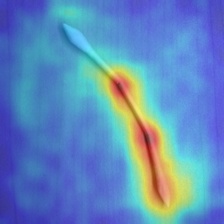
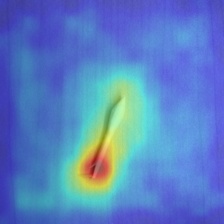
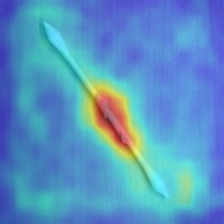
- 良品画像
- 異常箇所に境界線を引いた画像
閾値の設定をするには、良品の画像と不良品の画像の異常値を比較し、適切な値に設定する必要があります。- 良品画像
良品画像の検証の結果、境界線が無いことが分かる。これは、画像に異常箇所がないことを表している。

- 不良品画像
適切に閾値を設定することによって、不良箇所に境界線が引かれていることが分かる。







- 良品画像
まとめ
ここまで、外観検査AIモデル PatchCore を紹介していきました。PatchCore は2022年に外観検査で SOTA を達成しただけあって、異常箇所をかなり精度よく検出していることが分かります。ただし、良品の画像のみでモデルを作成することはできますが、正常・異常を分けるための閾値を設定するには、不良品の画像が必要になります。よって、実際の現場では、モデルの導入後であっても不良品の異常値に応じて適切に閾値を設定し、更新していく必要があります。
また、上記の実行結果でも記載したように、不良品画像を良品と判断した例がありました。一般的に、100%正しい判断ができるAIモデルはありません。しかし、このようなAIモデルを用いることによって、ヒューマンエラーを減らし、人件費やコストの削減を図ることが可能です。
補足
ここからは推論時における PatchCore のアルゴリズムを説明していきます。数式を用いて説明しているため、難しい方は読み飛ばしていただいで構いません。また、本論文と一部記号の定義内容が異なる箇所がありますが、ご了承ください。
下記の文字を導入します。
- Memory Bank : ${\mathcal M}$
- 学習時に実行した特徴量変換 : ${\mathcal P}$
- 推論画像データ : ${\mathcal D}$
正常・異常を判定したい画像データを $x_{\rm test} \in {\mathcal D}$ とする。また、
$$
{\mathcal M}_{\rm test} = {\mathcal P}(x_{\rm test})
$$
とする。このとき、画像単位の異常スコアは下記のように計算される。
- ${\mathcal M}_{\rm test}$ の各点に対して、${\mathcal M}$ の一番近い点を求める。ここではユークリッド距離が使われる。
$$
{\mathcal M}^*_{\rm test} = \left\{
(m, m_{\rm test}) \in {\mathcal M} \times {\mathcal M}_{\rm test}
\ | \
\underset{m \in {\mathcal M}}{\rm argmin}
\|m_{\rm test} – m \|_2
\right\}
$$ - $(m, m_{\rm test})$ のうち、一番距離が大きいペアを $(m^*, m^*_{\rm test})$ とする。
- $s^*=\|m^*_{\rm test} – m^* \|_2$ とすると、画像単位の異常スコアは
$$
s = \left(
1
– \frac{
\exp \|m^*_{\rm test} – m^* \|_2
}{
\displaystyle
\sum_{m \in {\mathcal N}_b(m^*_{\rm test})}
\exp \|m^*_{\rm test} – m \|_2
}
\right) \cdot s^*
$$
で求められる。ここで、$b \in {\mathbb N}$ に対し ${\mathcal N}_b(m^*_{\rm test}) \subset {\mathcal M}$ は、$m^*_{\rm test}$ から最も近い ${\mathcal M}$ の $b$ 個の点の集合である。(蛇足だが、$m^* \in {\mathcal N}_b(m^*_{\rm test})$ である。)
もし不良品画像であれば、$m^*_{\rm test}$ は異常箇所のピクセルの値が選ばれ、$m^*_{\rm test}$ と ${\mathcal M}$ の各点の距離は遠くなるはずである。よって、$s$ と $s^*$ が近い値を取るようになり、異常スコアが大きくなる。
ピクセル単位の異常スコアは下記のように計算される。
- パッチ単位の異常スコアを計算する。下記の式で求められる。
$$
{\mathcal S} = \left\{
\|m_{\rm test} – m\|_2
\ | \
(m, m_{\rm test}) \in {\mathcal M}^*_{\rm test}
\right\}
$$ - パッチの異常スコアは元画像のサイズより小さいので、ガウシアンフィルタによりアップスケーリングして元画像のサイズと同じ大きさにする。一般的には $\sigma = 4$ が用いられる。
参考文献
- https://arxiv.org/abs/2106.08265
Karsten Roth, Latha Pemula, Joaquin Zepeda, Bernhard Scholköpf, Thomas Brox, Peter Gehler, University of Tübingen, Amazon AWS: “Towards Total Recall in Industrial Anomaly Detection.”, arXiv:2106.08265 (2021) - https://zenn.dev/kwashizzz/articles/ml-anomaly-det-patchcore
- https://qiita.com/umapyoi/items/7c3e9b42388d576057b1
- https://github.com/amazon-science/patchcore-inspection
- https://paperswithcode.com/sota/anomaly-detection-on-mvtec-ad
注釈
- Niv Cohen and Yedid Hoshen, “Sub-Image Anomaly Detection with Deep Pyramid Correspondences”, (2020)
- Thomas Defard, Aleksandr Setkov, Angelique Loesch, Romaric Audigier, “PaDiM: a Patch Distribution Modeling Framework for Anomaly Detection and Localization”, (2020)
- 毎年アメリカで開催され、コンピュータビジョンに関する世界的な学会
- MVTec Software社が提供する外観検査向けデータセット
- State-of-the-Artのこと。ある分野のあるスコアで最高の性能を達成していること。
- 使用される学習済みモデルは主に Resnet18 や WideResnet50×2 である。
- Greedy アルゴリズムとも言われる。
- 1400万枚以上もあるほど大規模な、カラー写真の教師ラベル付き画像データベース
- ResNet18 などの深層学習モデルは、ImageNet の画像を用いて学習されることが多く、その際に正規化という処理が前処理として使われている。


