こんにちは。てくいの カワカミ(うぇるだん)です。
今回、私たち株式会社エクス テクノロジー・イノベーション本部では、株式会社レッジさん主催の画像分類コンテストに参加しました。
せっかくなので、コンペの概要やどんなふうに画像分類を行ったかをまとめておきます。
目次
はじめに
NNC Challengeとは
NNC Challenge (Neural Network Console Challenge)とは、「Sonyが提供するNeural Network Console(NNC)を使って与えられたお題に対する自分なりの解を出すコンテスト形式のオンラインイベント」です。 2020年3月4日 – 3月27日(提出期限が3月31日に延期)の期間で行われました。
コンテストは、Neural Network Console(以下、NNC)を用いてPIXTAの写真素材を分類するというもの。参加者に与えられたテーマは以下の4つです。
- 『人物画像をNNCで学習させ新しいオノマトペ(擬音語/擬声語/擬態語)の画像カテゴリ分類を作り出す』
例)ニコニコ/バチバチ/ゴリゴリ - 『画像内人物をNNCで学習させ画角/焦点距離による画像分類を作り出す』例)正面向き/バストアップ/全身/背面
- 『NNCで画像を学習し人の感情によって分類』
例)嬉しい/悲しい/恥ずかしい - 上記以外のチャレンジテーマを自由に設定しての応募も可
※ただし画像分類のテーマに限る
この中のいずれかのテーマでPIXTAから提供された10000枚の人物画像の分類を行い、その結果を提出することが今回のミッションです。うぉぉ。
Neural Network Console(NNC)
ソニーネットワークコミュニケーションズ株式会社が開発・運営する、ディープラーニングの開発基盤。GUI画面でドラッグ&ドロップにより簡単にニューラルネットワークを作成でき、PythonがかけなくてもすぐにAI開発が始められる。機械学習で使用するレイヤーを豊富に揃えているだけでなく、学習履歴の保存機能やネットワークの構造を自動で編集してくれる機能もあり、めちゃくちゃ便利。
チャレンジは突然に…
新型コロナウイルス感染症(COVID-19)のため、オフラインのイベント等がことごとく中止or延期になってしまい、寂しい思いを噛みしめていた3月のある日。2年ほど前に取得したG検定の合格者用slackチャンネルに気になる投稿が。
” Neural Network Console Challenge開催について “
なんだか気になったので調べてみると、なるほど前述のようなコンペティションの情報を得ることができました。お恥ずかしながら、このとき初めてNNCの存在を知りましたが、今まで見てきた「GUIでAIつくれるよ!」なサービス(製品)とは一線を画す使いやすさです。その理由は、
- ネットワークを作成するためのブロックが操作しやすい
- データ前処理の手間がほとんど必要ない
画像データもcsvでそのままアップロード&使用できる(しかもWindows版アプリなら対象データが格納されたフォルダを指定してそのまま使える) - チュートリアル動画(Youtube)が充実している
- サンプルプロジェクトに有名どころのモデルがかなり入っている
などが挙げられます。普段Pythonコードをゴリゴリ書いて頑張っている身としては、モデルやパラメータの調整の手間が圧倒的に少なく、神様のようなツールです。これは使ってみない手はないです。
ということで、TIメンバー全員でNNCチャレンジ(Neural Network Console Challenge)に挑戦することになりました。今回は各々がNNCの操作に慣れたり、コンペティションに触れ合う機会をふやしたりという目的もあったので、チーム参加ではなく個人参加です。
テーマ選択
選択したテーマ
①人物画像をNNCで学習させ新しいオノマトペの画像カテゴリ分類を作り出す
テーマ選択理由
-
- イメージで画像検索すると、画像が引っかからないことがある
- 新しい感覚で画像検索したい
分類カテゴリの決定方法
-
- slackなどのコミュニケーションツールでよく使われているものをピックアップ
- 現在、PIXTA上では検索結果が0件〜数件程度のものをチェック
- 最終的に5つのオノマトペを選出

今回選択したオノマトペ(学習用データ提供:PIXTA)
オノマトペとは
擬音語・擬声語・擬態語を包括的にいう語。キラキラ、ウキウキ、ザーザー など オノマトペとは何?Weblio辞書
データセットの作成
アノテーション
さっそく画像にアノテーションしていきます。
Average Hashで類似の画像をまとめる
PIXTAから提供された10,000点のデータから、選択したオノマトペ(わくてか、つよつよ、しゅっと、きゅんきゅん、わーきゃー)に当てはまる画像をいくつか選び、その画像とAverage Hashが近い画像を同じフォルダ内から選び、他のフォルダにコピーする。というプログラムを実行し、類似の画像を自動的に集めました。
# coding: utf-8
from PIL import Image
import numpy as np
import glob
import os
import shutil
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
size = 64 #圧縮サイズの指定
target_file = '*****' #類似検索対象の画像を指定
search_dir = '*****' #検索対象の画像(約10,000枚)が格納されているフォルダを指定
# ファイルの存在チェック
new_dir = target_file[13:-4]
myCheck = os.path.isdir(new_dir)
# 画像データをAverage hashに変換(グレースケール版)
# def average_hash(target_file, size):
# img = Image.open(target_file)
# img = img.convert('L').resize((size, size), Image.ANTIALIAS) # グレースケール変換&圧縮
# px = np.array(img.getdata()).reshape((size, size))
# avg = px.mean() # 画素値の平均値を取得
# px = 1 * (px > avg) # 画素データ(px)で平均より大きい要素を1に、それ以外は0に変換
# return px
# 画像データをAverage hashに変換(RGB版)
def average_hash(target_file, size):
img = Image.open(target_file)
img = img.resize((size, size), Image.ANTIALIAS) # 変換モードはRGB
px = np.array(img.getdata()).reshape((size, size, 3)) # リサイズの形状は3次元
avg = px.mean()
px = 1 * (px > avg)
return px
# 画像間のAverageHash値のハミング距離(要素が異なる部分の合計値を計算)を求める
def hamming_dist(a, b):
a = a.reshape(1, -1) # 1次元へ
b = b.reshape(1, -1) # 1次元へ
dist = (a != b).sum()
return dist
#対象ファイル名のフォルダがあるかチェックし、なければ作成する
def writeTxt(new_dir, myCheck):
if not myCheck: # 真(True)でない場合に実行
os.mkdir(new_dir)
-------
実行
-------
target_dist = average_hash(target_file, size)
images = glob.glob(os.path.join(search_dir, '*.jpg'))
rate =6.0
result = []
for i, fname in enumerate(images):
dist = average_hash(fname, size)
diff = hamming_dist(target_dist, dist) / 256
if diff < rate:
result.append([diff,fname])
writeTxt(new_dir, myCheck)
img = Image.open(target_file)
plt.imshow(img)
plt.tick_params(labelbottom='off',bottom='off') # x軸の削除
plt.tick_params(labelleft='off',left='off') # y軸の削除
plt.figure(figsize=(128,128))
plt.subplots_adjust(wspace=0.5,hspace=0.5)
for i, item in enumerate(result):
plt.subplot(100, 100, i+1)
img = cv2.imread(item[1], cv2.COLOR_BGR2RGB)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) #BGR -> RGB順に
plt.tick_params(labelbottom='off',bottom='off') # x軸の削除
plt.tick_params(labelleft='off',left='off') # y軸の削除
plt.imshow(img)
shutil.copy(item[1], new_dir)
手動で中身を調整する(根性)
プログラムで目的の画像を楽に自動で収集してみましたが、うーん、いまいち…。なんというかあんまり似ていない。「色や形」が似ているものを検索する際にはかなりいい結果を出すはずなんですが、今回のような「複雑な」画像かつ、「雰囲気」が似ているものを検索するのには向いていなかったかもしれません。確かに、これで分けられるなら機械学習なんていらないですよね(^◇^;)
ということで、ある程度ザックリ分け分けした各オノマトペフォルダを再度確認し、これは違うな〜という画像を取り除いていきました。落ち着いて考えると二度手間感がありますが、この時はとにかく必死だったので気が付きませんでした。
サイズ調整とアノテーション
苦労してフォルダ分けしたデータのサイズ調整を行い、NNCへのアップロード時に使用するcsvを作成します。
import os
import numpy as np
import cv2
import glob
import random
import shutil
import csv
# your original parms
class_num = 5
input_dir = '*****'
output_dir = input_dir
file_type = 'jpg'
test_size = 200
csv_prefix = 'nnc'
csv_header = ['x', 'y']
# image_size
# img_size = 64
# img_size = 128
img_size = 480
# grobal list
train_csv, test_csv = [], []
def img_resize(org_img):
gry = cv2.imread(org_img)
img = cv2.resize(gry,(img_size,img_size))
cv2.imwrite(org_img, img)
#ランダムにテストデータと訓練ようデータに分ける
def img_classification(i):
img_list = glob.glob('{}/{}/*.{}'.format(input_dir, i, file_type))
count = 1
for img in img_list:
if count <= test_size*2 and count%2 == 1:
img_resize(img)
shutil.copy(img, '{}/test'.format(output_dir))
test_csv.append([img, i-1])
else:
img_resize(img)
shutil.copy(img, '{}/train'.format(output_dir))
train_csv.append([img, i-1])
count += 1
def main():
# outputディレクトリがなければ作成
if not os.path.exists('{}/test'.format(output_dir)):
os.mkdir('{}/test'.format(output_dir))
if not os.path.exists('{}/train'.format(output_dir)):
os.mkdir('{}/train'.format(output_dir))
#画像をランダムサンプリング
for i in range(class_num+1):
img_classification(i)
#csvを出力
with open('{}/{}_test.csv'.format(output_dir, csv_prefix), 'w') as f:
writer = csv.writer(f)
writer.writerow(csv_header)
writer.writerows(test_csv)
with open('{}/{}_train.csv'.format(output_dir, csv_prefix), 'w') as f:
writer = csv.writer(f)
writer.writerow(csv_header)
writer.writerows(train_csv)
# 実行
if __name__ == '__main__':
main()
作成したcsvを使って、画像をNNCのデータセットにアプロードしていきます。アップロードの方法はNNCのサポートページに従います。アップロードしたロードしたデータセットは、以下のようにNNC画面に表示されます。
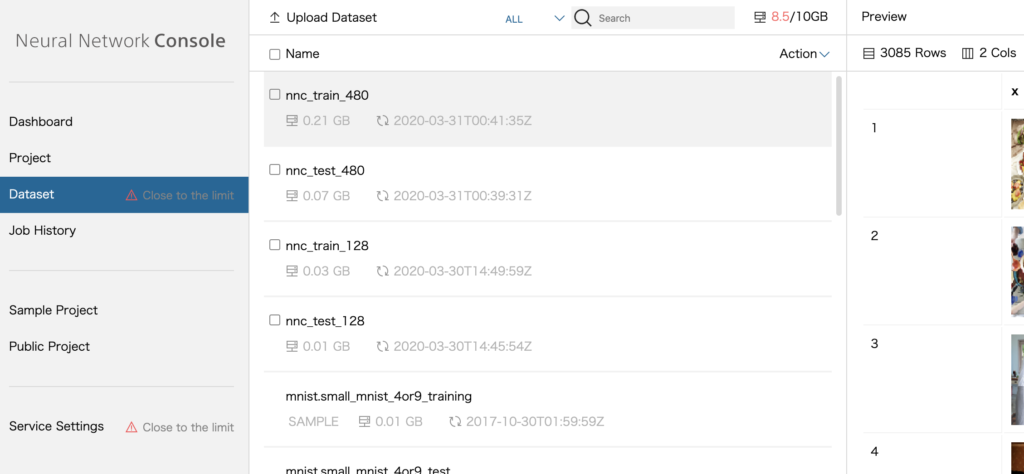
NNCデータセット
ネットワーク作成
まずは簡単なネットワーク
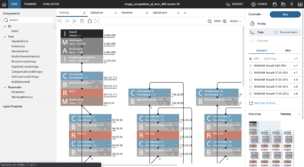
いよいよ本題のネットワーク設定に入っていきます。まずは画面操作に慣れるため、単純なCNNネットワークを作成してみました。まずC(Convolution:畳み込み層)、M(MaxPooling)、R(ReLU:活性化関数)またはT(Tanh:活性化関数)のレイヤーを2つ重ね、A(Affine:全結合層)から出力層に繋げます。B(BatchNormalization)は使用しませんでした。
ネットワークの作成は、ブロックを繋げてネットワークを作成したあと、I(Input:入力層)のサイズ、C(Convolution)のカーネルサイズやストライドなどのフィルター設計、出力層へ向けたA(Affine)の出力サイズを調整するくらいで完了です。入力層から順に設定していくと後方に接続しているブロックの入力サイズや出力サイズは自動で計算されていくので、圧倒的にNOミスです。あとは、[DATASET]タブで先ほどアップロードしたデータセットをtraining用、validation用それぞれにセットし、[CONFIG]タブでepoch数やバッチサイズ、学習率などを設定するだけで作業は終了。実行ボタン(Run)を押してコーヒーでも飲みつつ待つだけで、ぬるっと学習が完了します。
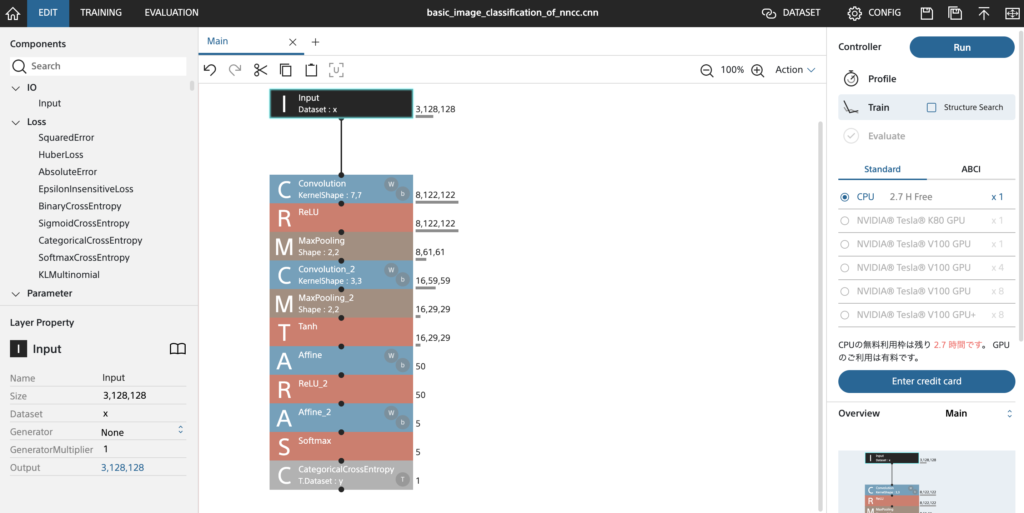
NNCでネットワーク設計
Global Configでepochやバッチサイズを指定します。
画面下にStructure Search(構造探索)モードという機能を使用するかどうかのチェックボックスがあります。これはネットワークの構造を解析し、より精度をあげるよう構造に自動で変換・学習を繰り返し実行するという機能です。ネットワークの構造探索にはパラメータに基づいたものとランダムなものがあり、延々学習を実行し続けられるような環境であればランダムの方が結果的に精度が高くなりやすいらしいです。私は今回は自分の設計したネットワークをよくわからない構造に変えられたくなかったので、このモードはOFFにしました。
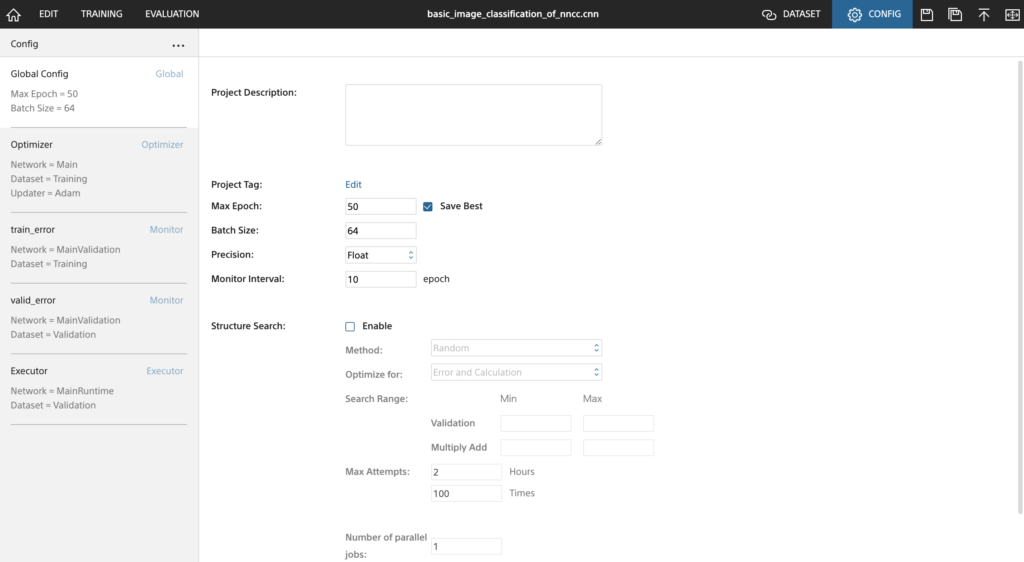
NNC学習時の設定①
さらにOptimizer以下で損失関数や学習率などのハイパーパラメータを調整します。
NNC学習時の設定②
学習の様子です。指定したタイミングで学習の途中経過がアウトプットされていきます。
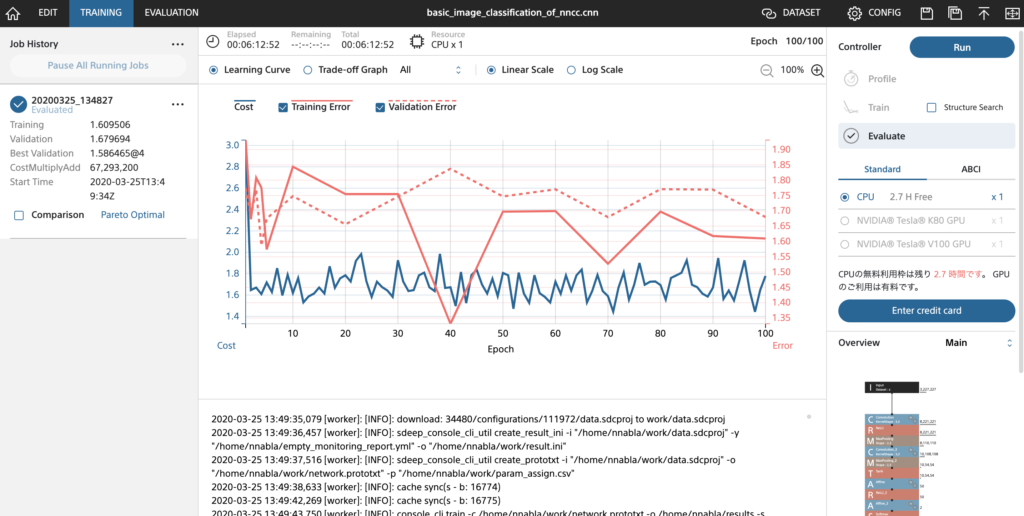
NNC学習の様子
まずは雰囲気を感じるため、inputのサイズを32×32、64×64、128×128とちょっとずつ上げて50〜100 epochほど学習してみましたが、いずれも精度は30%程度でした。この時点で、おそらく結構複雑なネットワークでないと精度が上がらなそうだと感じ、思い切ってResNetを使用することにしました。
ResNet
ResNetとは
ResNetは、2015年にMicrosoftが発表した152層からなるニューラルネットワークです。それまでの20層程度のネットワークとは異なり、最大で1201層まで層を増やすことができます。ニューラルネットワークにおいて層を増やすということは、より複雑な特徴量の抽出を可能とするため、精度の高い画像認識を可能とします。このネットワークをベースとすることで効率よく学習を進めます。
具体的な実装では、ブロック(畳み込み・バッチ正規化・活性化関数をひとまとまりとしたレイヤー)が順序よく繋がっているだけでなく、各ブロックをショートカットするコネクションも存在しています。これによってweightの調整が必要ないブロックを飛ばすことができ(これをshortcut connectionといいます)、層が深くても勾配消失問題を起こしにくく、効率よく学習を進められるらしいです。面白いアイデアです。
今回は軽量版のResNet-18を試してみました。
ResNet-18の実装
NNCプロジェクト上ではTraining、Validation、Runtime、Validation5の4つのネットワークからなります。こちらはサンプルプロジェクトとして公開されているものを引用して作成しました。NNCのいいところは、先に説明したパラメータサイズの自動計算機能などネットワーク構築サポートによる実装のしやすさだけでなく、有名なモデルを使ったプロジェクトサンプルの豊富さだと思います。今回の課題では触れる機会はありませんでしたが、私が興味を持っている「GAN」のサンプルもあったので近いうちに触ってみたいと思います。
はなしが横道にそれましたが、図のような複雑なモデルもさくっさくっと作り終わりました!学習の実行の設定方法は最初に作ったネットワークとほぼ同じです。
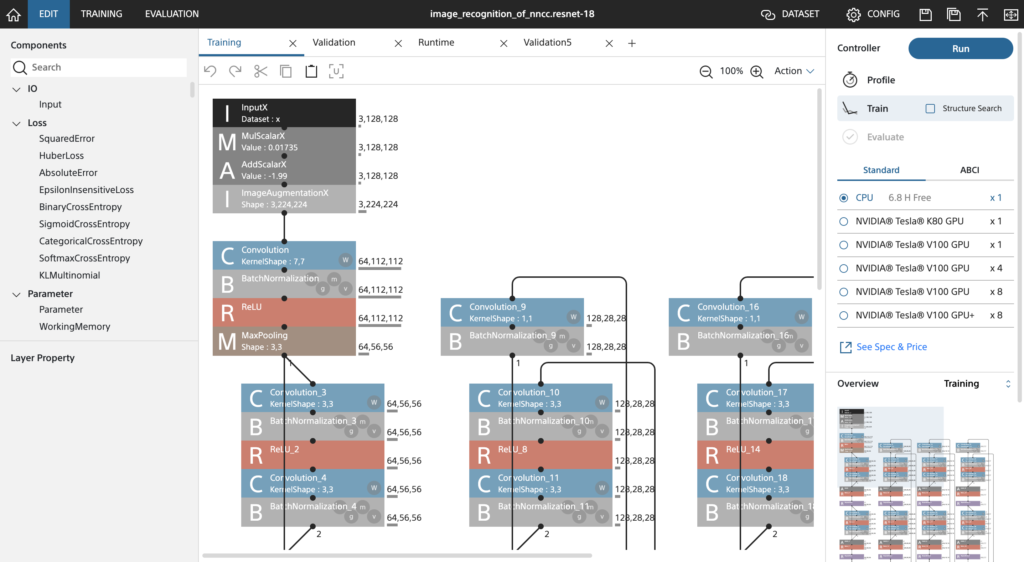
ResNet-18のトレーニングネットワーク
補足:ResNet-50
ResNet-18だけでなくもう少し層を深くしたResNet-50も使用してみましたが、精度はあまり変わらなかったので今回は割愛します。AlexNetやResNet-18比較した論文(M. Talo et al, 2019)でははっきりと差がみられますが、今回は差がないどころかAccuracy Rateは45%程度でした。
精度上げ(パラメータ等の調整)
さて、学習を進める中でより高い精度を出すため、いくつかトライできることがあります。
-
- ハイパーパラメータの調整
- 過去論文など参考にしながら一般的な範囲で各種パラメータを触ってみるのは結構有効かと思います
- 再学習
- NNCでは学習結果が自動的に保存されます
- この保存された調整済みの重みをそのまま使って再学習を行うことがボタン1つでで可能です
- Inputサイズの調整
- 各レイヤーの調整
- とくに畳み込み層のフィルターの大きさや動かし方、プーリング層のサイズなどが特徴量の抽出に影響します
- 活性化関数の選択によって、勾配の消失などに対応できることもあります
- ハイパーパラメータの調整
今回は、各レイヤーの調整以外を一通り試してみました。
学習結果と考察
学習結果
学習結果です。
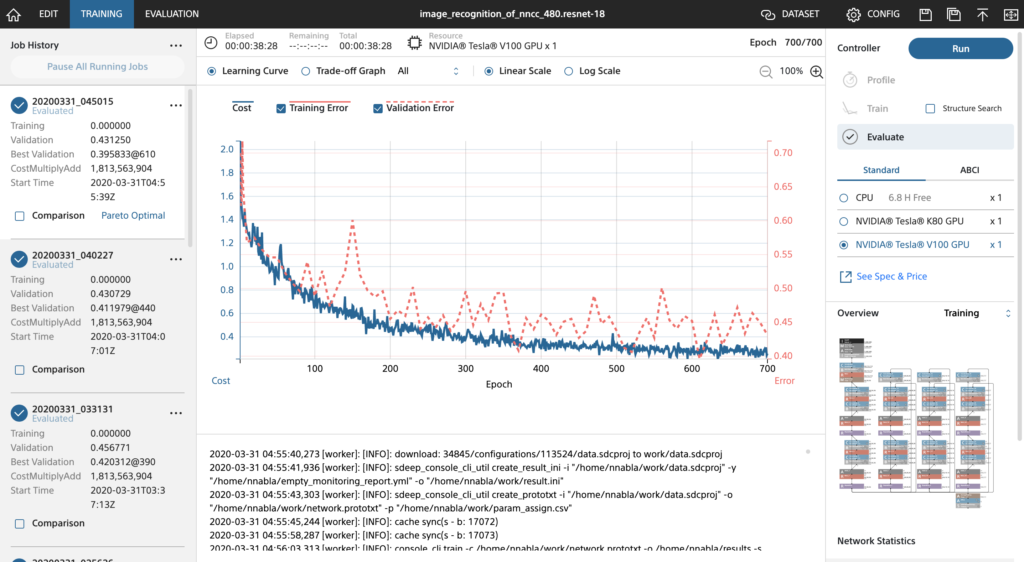
NNC学習の様子(ResNet-18)
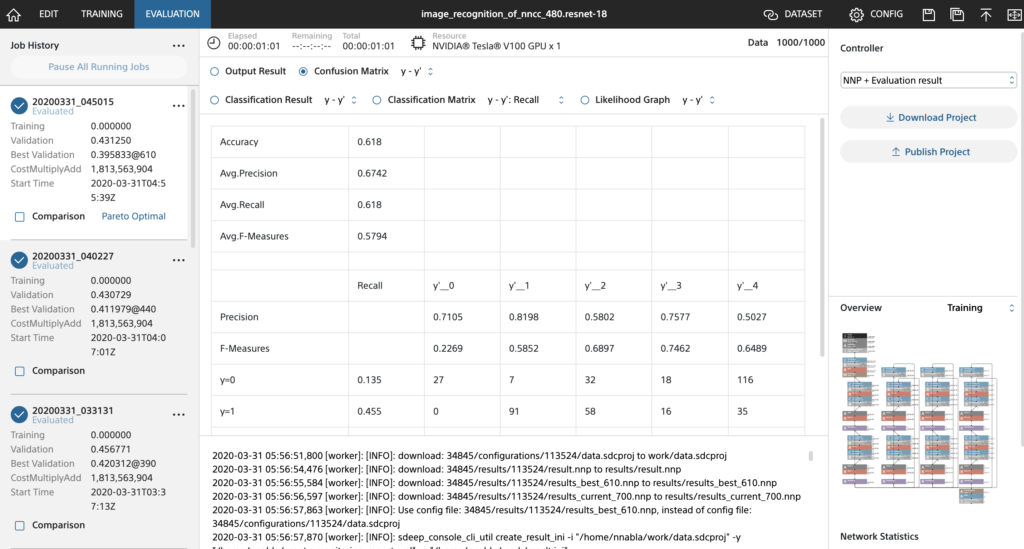
NNC学習結果
考察
最終的に精度は62%程度までしか上がりませんでした。原因は割と明らかで、以下が挙げられます。
-
- データサイズが小さい
- 各クラス、訓練データ700・テストデータ200しか集められなかったので母集団を捉えきれなかった可能性は高いです
- じつは訓練データに至ってはクラス間で30程度データサイズにばらつきがあるまま進めてしまいました。データセットが少ない状態で、この差は想像よりインパクトが大きかったかもしれません
- 分類がそもそも曖昧
- モデル選択のところでも紹介しましたが、今回ResNet-50というより層の深いモデルでは精度が全然上がりませんでした。これは、アノテーションが曖昧でデータが汚かったことが主な原因かと思います。
分類基準を「感情」とする場合はラベル間にはっきりと違いがあるものを選んだり、同じアノテーション作業を複数人で数回行ったりという工夫が必要なことに気がつきました。
- モデル選択のところでも紹介しましたが、今回ResNet-50というより層の深いモデルでは精度が全然上がりませんでした。これは、アノテーションが曖昧でデータが汚かったことが主な原因かと思います。
- 同じファイルが複数のクラスで重複している
- 課題へのアプローチを「画像に対してオノマトペのタグをつける」としたため、同じ画像に複数のオノマトペが正解となるのはOKとしました。そのため正解を1つとするような正解率の出し方)
- データサイズが小さい
パラメータ調整の効果については、
-
- ハイパーパラメータの調整
- パラメータ調整前でもepoch50くらいで十分Validation エラーが下がっていたりと、あまり効果はありませんでした。多分。
- 再学習
- 単純に学習回数が増やせたので、徐々に精度は上がっていきました。
- ただし、これを延々続けるのはコスパ的になしかなと思い、途中でやめました(飽きたともいう)。
- Inputサイズの調整
- 今回、32×32、128×128、480×480の3種類の画像サイズへデータセットを調整して学習を行なってみました。調整はアスペクト比は固定しないで単純にリサイズしただけです。
- 結果としては32×32と128×128ではかなり精度が向上(30%→60%)しましたが、480×480では大して変わりませんでした。
- ハイパーパラメータの調整
余談ですが、学習の実行環境についてもちょっと比較しておきます。ResNet-18(データセットのサイズは画像数:3000程度、画像サイズ:128×128)で100 epochの学習を行う場合、CPUだと45時間ほどかかってしまうところ、大会の運営のご好意によりお借りしたGPU環境(NVIDIA®︎ Tesla V100)では6分程度と驚異的な速度の違いを感じられました。これが時間あたり約500円で使えるのはすごいですね。
まとめ
紆余曲折、山あり谷ありのNNCチャレンジでしたが、今回のチャレンジのまとめとしては以下の成果・知見(教訓)がえられました。
- 画像に対してなんとなくオノマトペ追加ができた(画像の雰囲気がモデルで表現できた)
- 分類基準を「感情」とする場合、いつも・誰でも同じように分類できる課題にしないといけない
- 精度上げはもう少し勉強していかないといけない
- NNCはメッチャ使いやすかった
最後に、このような貴重な体験&学習をもたらしてくださった株式会社レッジさん、Sonyさん、株式会社PIXTAさんへ厚く御礼申し上げます!!
コメント
Comments are closed.