こんにちは!
株式会社エクス、アドバンスドテクノロジー部所属の@tsum_tsumです!
ChatGPT が発表されて以降、大規模言語モデル( Large Language Model; 本ブログでは以下 LLM )の研究が盛んに行われています。テレビなどの様々なメディアでも、ChatGPT という言葉を聞くことが増えたような気がします…。そんな ChatGPT に代表される LLM ですが、入力する文章に対して優れた出力が得られるようになったので、
- 質疑応答
- 文章要約
- 翻訳
- 文章校正
など、様々な用途で使われていますね!
一方で、現在でも LLM に問題点が多くあります。その中の一つに、最新の情報やクローズドな情報を取得できないという問題があります。例えば、「最も新しいアメリカの大統領は誰ですか?」と ChatGPT に聞いても、下記のような返答しかしてくれません…
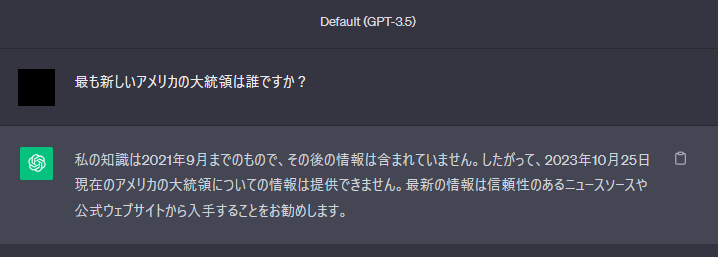
ChatGPT-3.5 の場合、その学習データには 570GB のテキストデータが用いられています。しかし、学習データの中に無い質問には答えることができません。上記の例では、学習に用いたテキストデータが2021年9月までしかないと明記されているため、2023年時点のアメリカの大統領を答えてくれるはずがありません…。では、最新の情報や社内規定のようなクローズドな情報を答えてもらえるようにするには、どうすればいいでしょうか?
目次
LLM に最新情報を答えさせるためには??
LLM に最新の情報を答えさせるためには、大きく分けて 2 パターン存在します。
- LLM に学習データとして最新情報を与え Fine-tuning する。または新しく作る。
- LLM に最新情報を外部情報として与え、要約してもらう。
前者の( LLM の Fine-tuning を行う)場合、膨大な GPU マシンが必要になります。長時間の稼働も必要になるため、費用が大きな課題になります。現在では、QLoRA などの少量の GPU マシンで学習できる手法も開発されています。
QLoRA とは?
QLoRA は LoRA(Low-Rank Adaption)と呼ばれる、元の重み行列のパラメータを固定し、より次元の小さい行列の積で近似することで学習パラメータの量を抑えた手法を、量子化すことによって学習パラメータの量を更に抑えた手法です。先日まで行われていた Kaggle の LLM Science Exam においても、限られた Jupyter Notebook の環境を最大限に用いるために、多くの上位チームで QLoRA が使われていました。しかし、それでも GPU マシンが必要になることに変わりありません。
最近では、OpenAI が提供している GPT3.5-turbo で Fine-tuning ができるようになりました。学習データを用意し API を実行するだけでよいので、GPU マシンを必要とせず従量課金である点も長所です。このサービスによって、前者の方法を用いるハードルが下がって、選択肢の1つに挙げられるようになりました。
Fine-tuning の問題点
しかし、Fine-tuning を方法であってもまだ問題点があります。それは、最新の情報やクローズドな情報は常に更新される可能性があるという点です。先ほどの質問「最も新しいアメリカの大統領は誰ですか?」は、いつ更新されるか分からない情報ですし、社内規定のようなクローズドな情報であっても、いつ更新されるかわかりません。そのような情報に対して、更新するたびに LLM を Fine-tuning するのはかなり非効率になってしまいます。
そこで、現在注目されている手法として、後者の方法(LLM に最新情報を外部情報として与え、要約してもらう)が挙げられます。最新情報や社内情報をあらかじめデータベースなどに保存しておき、LLM がそれを参照して、要約してもらい出力を得るという方法です。この手法は Retrieval Augmented Generation(以下 RAG )と呼ばれており、前者で挙げた問題点を解消できる方法として注目されています。
なお、ここで注意ですが、上記のリンクにある Meta 社が発表した RAG と今回紹介する RAG とは少し違うものになっています。Meta 社が発表した狭義の RAG に対し、世間一般に広まっている広義の RAG は Grounding と呼ばれる手法の一種とされています。今回は広義の RAG について説明していこうと思いますので、ご理解いただければと思います。
RAG とは?
ここからは RAG について説明していきます。RAG には大きく分けて 2 つのフェーズが存在します。
- Retrieval
- Generation
まず、最新情報やクローズドな情報をあらかじめ、データベースに保存します。Retrieval フェーズでは、入力された文章から回答に必要だと思われる情報をデータベースから検索して取得します。入力された文章から回答に必要な文章を取得するには、文章同士の”類似度”を測る必要があります。この”類似度”を測るための手法は、次のような方法が一般的に用いられます。
また、それぞれの手法で得た類似度を組み合わせて計算するハイブリッド検索も広く使われています。
Generation フェーズでは、Retrieval フェーズで取得した文章と入力された文章をセットで LLM に渡し、回答を生成します。LLM は新しい知識を外部から得て、その文章を要約しているだけなので、Fine-tuning のような追加の学習をすることなく、最新の情報やクローズドな情報を回答することができます。社内データを用いた回答生成 bot を例に、RAGの一連の流れを図示すると下記のようになります。
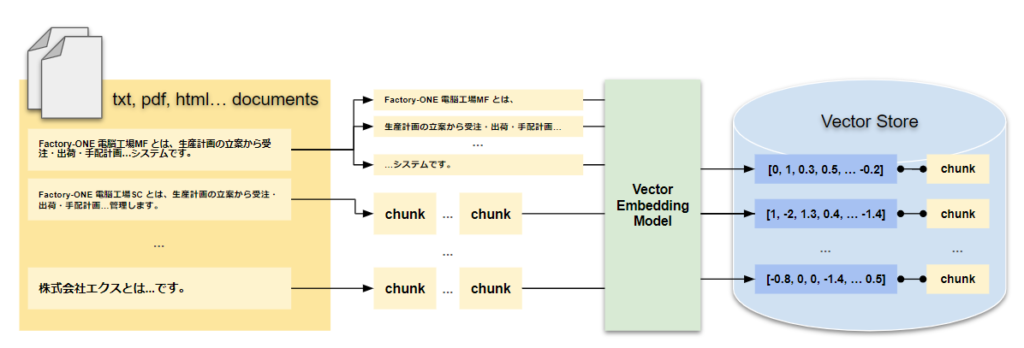
学習時
RAG の実行環境を作成したいとき、大きく分けると「学習」と「推論」の 2 つの環境が必要になります。
まずはあらかじめ用意していた文章をデータベースに保存します。文章をチャンク(文章を切り分けた後の文章のこと)に切り分けて、Vector Embedding Model(ベクトル埋め込みモデル)を用いて、ベクトルに変換します。その後、元のチャンクとベクトルをセットにして、データベースに保存します。
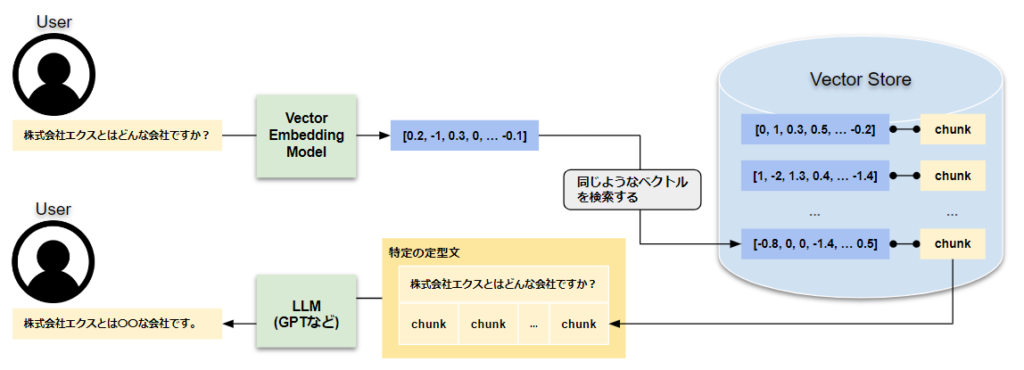
推論時
RAG の実際に質問する場合、まず質問文をベクトル化します。学習時に作成しておいたデータベースに似たようなベクトルを検索し、そのベクトルに紐づく文章を取得します。取得した文章、質問文をあらかじめ作成しておいた定型文に当てはめ、LLM に渡すことによって回答を生成します。
終わりに
今回は LLM に最新情報やクローズドな情報を生成させる方法として、RAG という仕組みを紹介しました。次回は RAG を開発する際に使用する、環境の設定についてお話したいと思います!!!




コメント
Comments are closed.