皆さんこんにちは、マツムラです。一気に冷え込み、PC排熱で暖を取り始める季節になりました。
本記事ではOpenAIより提供されている音声認識AIモデル”Whisper”を、GoogleColaboratoryで動かしてみます。またWhisperモデルを動かすだけではなくWhisperAPIの方でも音声認識をしますので、Whisperに興味ある方は是非ご覧ください。
はじめにWhisperを動かす前に音声認識の歴史や使われている技術について簡単に触れていきたいと思います。実際に動かすところからご覧になりたい方は、音声認識をしてみるからご覧ください。
目次
音声認識って?
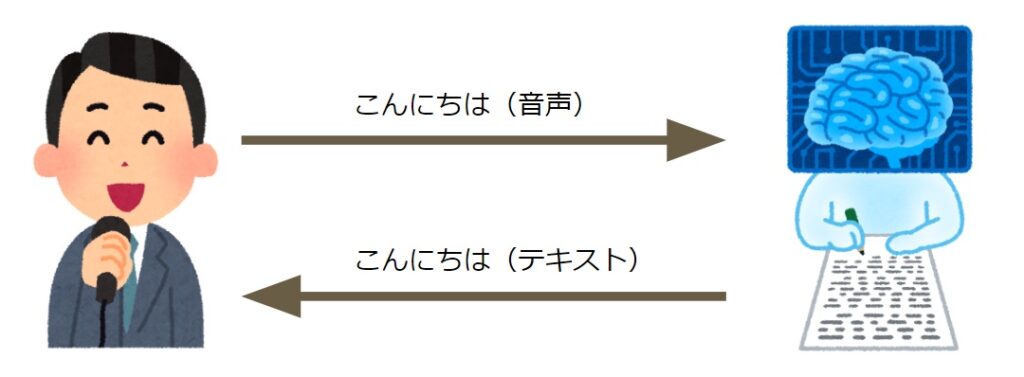
人間が話した声を解析し、テキストに変換する技術のことです。
例えば、私が「こんにちは」と言うと、テキストで「こんにちは」と返してくれます。
音声認識技術の登場
ここからは、音声認識の歴史について軽く触れておきましょう。
1952年、はじめての音声技術として「Audrey」が登場しました。「Audrey」はアメリカのベル研究所によって開発され、”1”から”9”までの音声を認識可能としていました。このブログを執筆している現在が2023年なので、2023 年なので、実に 70 年以上前には音声認識システムが世の中に公開されていたことになります。
続いて、1961年に登場したのが「Shoebox」です。「Shoebox」はIBMによって開発され、”0”から”9”までの数字やプラス、マイナスを含む16の話し言葉を認識することが可能で、簡単な足し算や引き算を実行することが可能でした。Shoeboxを動かしている様子はIBMのこちらの動画で見られますので、興味のある方は是非一度ご覧ください。
音声認識技術において「Audrey」と「Shoebox」が音声認識システムの先駆けとなりました。時が経つにつれ、音声技術はどんどん身近なものになっていきました。例として、1998年に任天堂から発売されたピカチュウげんきでちゅうの登場により、誰でも遊びの中でも音声技術を体験できるようになりました。さらに、2011年にSiriが、2014年にAlexa等のホームデバイスが登場し、普段の生活の中で見かけない日はないほどに音声認識は普及しました。
音声認識技術の進化
音声認識技術の歴史において、1980年代から1990年代にかけて隠れマルコフモデル(HMM)が音声の統計的モデリングに利用されるなど、重要な役割を果たしていました。
続いて2000年代にはガウス混合モデル(GMM)とHMMを組み合わせた、GMM-HMMモデルが広く活用されました。このモデルの組み合わせによって音声の複雑なパターンをより効果的に捉えることが可能となり、精度向上に寄与しました。
2010年代初頭には、ディープニューラルネットワーク(DNN)を基盤としたDNN-HMMモデルが導入され、ディープラーニングによって複雑な音響モデルや言語モデルの学習が可能となり、音声認識の精度は飛躍的に向上しました。
そして、2010年代後半から2020年代初頭にかけて、End-to-Endモデルへと進化しました。GMM-HMMモデルとDNN-HMMモデルは複数のモデルを組み合わせ、それぞれが別々の計算をしていました。そこから計算機、GPUやCPUの発展に並んで、End-to-Endモデルは音声認識のプロセスを一体化させ、より効率的なモデリングを可能にしました。
最近の音声認識
最近の音声認識としてOpenAI社の「Whisper」、Meta社の「Massively Multilingual Speech」や「SeamlessM4T」、今年の初めには株式会社レアゾン・ホールディングスが日本語の音声認識モデルの「ReazonSpeech」を公開しています。また、GoogleやAmazonなどクラウドサービスを提供している企業の多くが、音声認識APIサービスを提供しています。
音声認識をしてみる
それではOpenAIが公開した音声認識モデルの”Whisper”を利用して音声認識を行っていきます。
WhisperはOpenAIが文字起こしサービスとして公開した無料の音声認識モデルです。Webから収集した68万時間分の多言語音声データを教師付きデータで学習させており、高い精度で入力した音声を文字起こしすることが可能となっています。
まず最初にGoogleColaboratoryに接続しノートブックを新規作成します。ノートブックの設定からGPUを使用するように設定します。GoogleColaboratoryの設定方法は、YOLOXを動かしたときの記事に詳しくまとめていますので、画面を見ながら設定したい方は是非下記リンクをチェックしてみてください。
GoogleColaboratoryのセッションストレージに用意した音声ファイルを配置していきます。
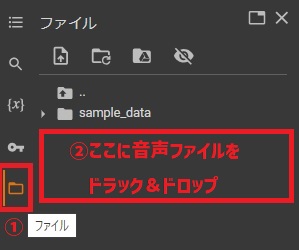
左のバーのファイルをクリックし、開いた箇所(下記画像の赤枠部分)へ音声認識させたい音声ファイルをドラック&ドロップします。
音声認識で使用する音声ファイルをVOICEVOX(VOICEVOX:冥鳴ひまり)で作成しました。
コードに下記ソースを記入し、任意の音声ファイル名をセッションストレージに配置した音声ファイル名に変更します。
# 音声認識をする
!pip install git+https://github.com/openai/whisper.git
import whisper
model = whisper.load_model("base")
result = model.transcribe("任意の音声ファイル名.拡張子")
print("音声認識結果: "+ result["text"])これで準備が完了したので実行してみます。実行完了後最後の行に認識結果が出力されます。
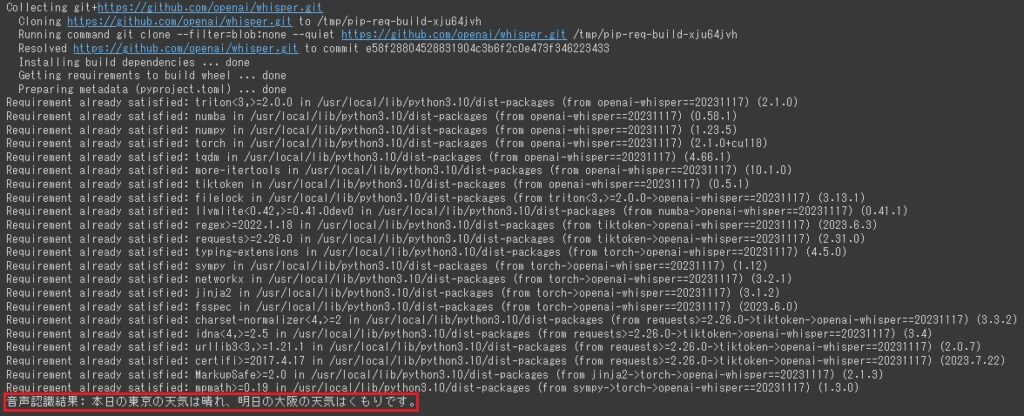
無事音声認識がされ、認識結果が表示されているのを確認できました。
今回”base”で音声認識を行いましたが、他にもモデルが用意されています。せっかくなので最新の”large-v3”にモデルを変更してもう一度音声認識を行ってみましょう。
large-v3を使用するためには、5行目のモデル名をbaseからlarge-v3に変更するだけで大丈夫です。
model = whisper.load_model("large-v3")変更が完了したら再度実行してみます。実行完了後最後の行に認識結果が出力されます。
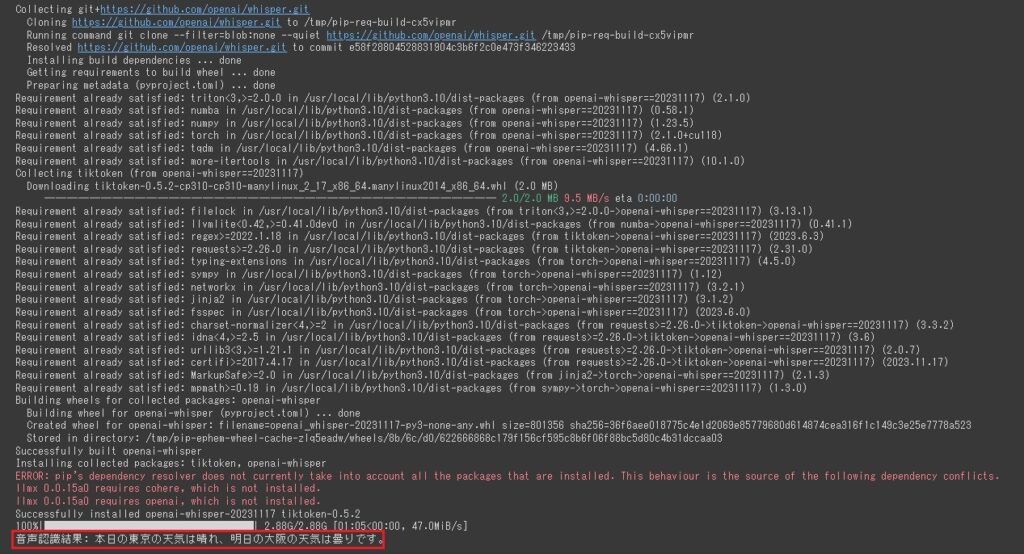
音声認識としてはbaseでも問題ありませんでしたが、large-v3の場合くもりが漢字で表示されました。他に利用可能なモデルはWhisperのGitHubに一覧で記載されていますので、ご確認ください。
もっと音声認識をしてみる
ここまで、OpenAIの音声認識モデル”Whisper”を使って、音声認識をやってみました。OpenAIが提供しているWhisperはモデルデータだけでなくAPIもあるので、今度はAPIを使って音声認識をしてみたいと思います。
WhisperのAPI利用は有料となっており、現時点(2023/12/05)で$0.006 /分 となっています。詳細はPricingページをご確認ください。
先ほどと同じようにGoogleColaboratoryのノートブックを用意し、セッションストレージに用意した音声ファイルを配置していきます。今回はCPUでも動くためノートブック設定は不要です。
コードに下記ソースを記入し、最初にOPENAI_API_KEYを取得したAPIキーに差し替えます。APIキーはここから発行と取得ができます。OPENAI_API_KEYは大切ですので取り扱いにはご注意ください。詳細はAPI referenceをご確認ください。
組織所属の場合OrganizationIDを自分の組織IDに差し替える必要があります。組織IDはここで確認することができるので、必要な方はご確認ください。組織に所属していない人は該当部分をコメントアウトするか、削除するようにしてください。
最後に任意の音声ファイル名をセッションストレージに配置した音声ファイル名に変更します。
# パッケージのインストール
!pip install openai
import os
from openai import OpenAI
# OPENAI_API_KEYを取得したAPIキーのものに差し替える
os.environ["OPENAI_API_KEY"] = "OPENAI_API_KEY"
client = OpenAI(
# APIリクエストを指定した組織の利用としてみなす場合
# OrganizationIDを自分の組織IDに差し替える
# 個人で課金している場合は設定の必要がないのでコメントアウトか削除してください。
organization='OrganizationID',
)
client.models.list()
audio_file= open("任意の音声ファイル名.拡張子", "rb")
transcript = client.audio.transcriptions.create(
model="whisper-1",
file=audio_file,
response_format="text"
)
print("音声認識結果: "+ transcript)準備が完了したので実行してみます。実行完了後最後の行に認識結果が出力されます。
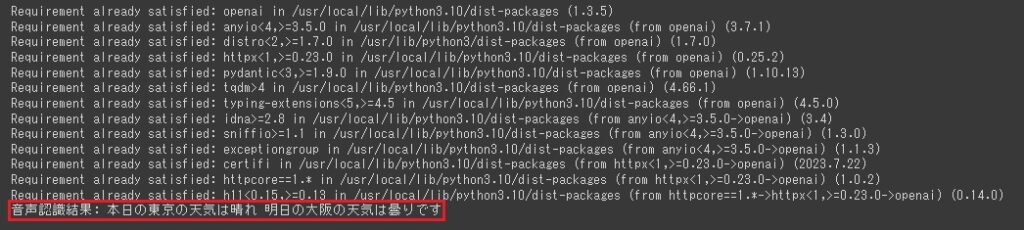
無事APIを使用して音声認識がされているのを確認できました。
今回利用したWhisperAPIは音声認識した後翻訳することもできます。せっかくなので先ほどの音声を英語にしてもらおうと思います。
現時点では英語への翻訳のみサポートしています。詳しくはドキュメントをご確認ください。
# パッケージのインストール
!pip install openai
import os
from openai import OpenAI
# OPENAI_API_KEYを取得したものに差し替える
os.environ["OPENAI_API_KEY"] = "OPENAI_API_KEY"
client = OpenAI(
# APIリクエストを指定した組織の利用としてカウントさせる場合
# OrganizationIDを自分の組織IDに差し替える
# 個人で課金している場合は設定の必要がないのでコメントアウトか削除してください。
organization='OrganizationID',
)
client.models.list()
audio_file= open("任意の音声ファイル名.拡張子", "rb")
transcript = client.audio.translations.create(
model="whisper-1",
file=audio_file,
response_format="text"
)
print("音声認識結果: "+ transcript)準備が完了したので実行してみます。実行完了後最後の行に認識結果が出力されます。
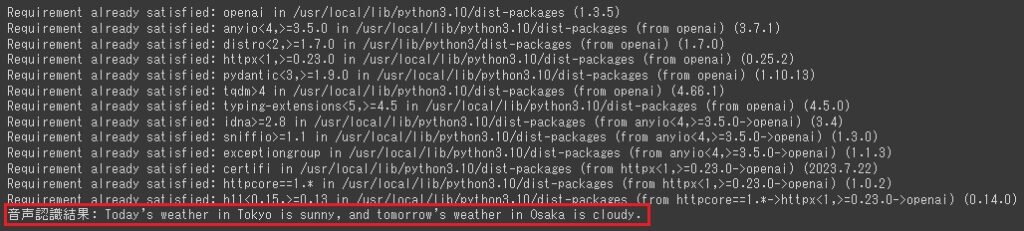
無事に英語に翻訳されていることを確認できました。
終わりに
今回OpenAIのWhisperを使用した音声認識の実際の手順やAPIを活用した操作を紹介しました。
音声認識はWhisper以外にも様々なモデル、APIサービスがあります。是非自身の目的に合うものを探して試してみてください。

コメント
Comments are closed.