
Kaggleでデータ分析に入門してみよう!シリーズ2回目ですが、前回のアカウント作成から早半年が経過してしまいました…もう少し真面目に取り組みたいものです。さて今回は、Kaggleを始めるほとんど全ての人が通る道、「Titanic : Machine Learning from Disaster」というタイタニック号の事故から生還するのは誰かを予測するタスクに挑戦して、実際にSubmitするところまでをまとめていきます。
目次
タイタニックとは?
Kaggleの初心者向けタスクの中でも、とくに有名なのが「Titanic : Machine Learning from Disaster」です。直訳すると「タイタニック:災害からの機械学習」でしょうか。よく、「タイタニック、タイタニック」と呼ばれているのがこのタスクですね。具体的には、歴史的にも有名なタイタニック座礁事故を題材に、乗客の生死を予測するという課題です。乗客のデータとしては、性別や年齢、客室のランク(社会経済的階級)、同乗者の有無などが与えられていて、それらの情報から機械学習で乗客の生死を予測していきます。非常にシンプルかつデータ量も多くないことから、Kaggleだけでなくデータ分析や機械学習の初級者でも取り組みやすい題材となっています。
Competition:コンペの中身を確認しよう
Kaggleは世界中の機械学習やデータサイエンスに関わる人々が集まるコミュニティです。主なコンテンツとしては、「Competition(コンペ)」という、企業や政府がコンペ形式で提示する課題があります。コンペには賞金がかけられていることが多く、精度上位の分析モデルには賞金が支払われたり、ヘッドハンティングのきっかけになったりします。
まずは、今回挑戦するタイタニックのコンペページをみていきます。
Overview
Description
コンペの概要が説明されています。以下、要約です。
概要:
本コンペは、機械学習コンペティションや、Kaggleプラットフォームの仕組みに慣れるための最初の課題です。
コンペの内容は単純で、機械学習を使用して、タイタニック号の海難事故を生き延びた乗客を予測するモデルを作成します。コンペの詳細:
タイタニック号は、当時、最新鋭の設備により「不没船」と呼ばれた世界最大の客船でしたが、1912年4月15日、処女航海中に氷山と衝突して沈没しました。2224人の乗員乗客のうち1502人が死亡するという、歴史上最悪の海難事故の1つです。この事故で生き残った人には、強運以外にある特定の条件があったようです。
この課題では、与えられた乗客データ(名前、年齢、性別、社会経済的階級など)を使用し、「どのような人々が生き残る可能性が高いか」という質問に答える予測モデルを構築します。Kaggleコンペの仕組み:
1.コンテストに参加する
チャレンジの説明を読み、規約・ルールに同意して、データセットにアクセスします。2.モデルを構築する
ローカルまたはKaggleNotebookでモデルを構築し、予測ファイルを生成します。3.提出する
予測をKaggleへアップロードし、精度スコアを受け取ります。4.リーダーボードを確認する
リーダーボードで、モデルがどのようにランク付けされているかを確認してください。5.スコアを向上させる
ディスカッションフォーラムをチェックして、課題提供者や参加者からの情報を見つけてください。データの概要:
名前、年齢、性別、社会経済階級などの乗客情報を含む2つの同様のデータセットにアクセスできます。
データセットは訓練用データ「train.csv」とテストデータ「test.csv」の2ファイルです 。
train.csvには、乗客の891名分のステータスが含まれます。このデータには彼らが生き残ったかどうかの情報も含まれます。
test.csvには同様の情報が含まれていますが、各乗客の生死は開示されていません。
train.csvのデータで見つけたパターンを使用して、他の418人の乗客(test.csv)が生き残ったかどうかを予測するのが本コンペのゴールです。課題の提出方法:
1.「Submmit」ボタンをクリックします
2.CSVファイルを送信ファイル形式でアップロードします。 1日に10件の投稿を送信できます。提出ファイル形式:
乗客418名分のエントリとヘッダー行を含むcsvファイルを送信します。
ファイルにPassengerIdとSurvived以外の不要な列がある場合、エラーが表示されます。
Evaluation
評価方法や、課題提出方法について記載されています。
タイタニックでは、418件のテストデータに対して、乗客の生死を予測し、乗客IDと生死のバイナリ(生還:1、死亡:0)の2列からなるcsvファイルを提出します。評価はその正解率(accuracy)で行われます。

418の乗客データに対応するPassengerId、Survivedの2列からなるcsvを提出します
Timeline
コンペの開始日と期限などが記載されています。タイタニックは常時開催の為、このメニューはありません。
Prizes
賞金についてが記載されています。タイタニックには賞金がない為、このメニューはありません。
その他
その他、コンペによって追加情報が提供される場合があります。よく読んで参加しましょう。
Data
Data Description
データについて説明されています。
Data Explorer
提供されたデータセットを外観することができます。タイタニックコンペで提供されるのは、3つのcsvファイルです。
●gender_submission.csv
提出ファイルの例です。このファイルは女性だけが生き残ることを前提をした予測結果です。
●test.csv
予測に使用するファイルです。訓練用csvではSurvived
●train.csv
モデルの学習に使用するファイルです。
PassengerId、Sex、Survivedなど12カラムから構成される891のデータからなります。
| PassengerId | 乗客ID |
| Survived |
生き残り(1 = 生存、0 = 死亡) |
| Pclass |
チケットのクラス( 1 = 1等,、2 = 2等、 3 = 3等) |
| Name | 名前 |
| Sex | 性別 |
| Age | 年齢 |
| SibSp | タイタニック号に同乗している配偶者/兄弟の数 |
| Parch | タイタニック号に同乗している親/子供の数 |
| Ticket | チケット番号 |
| Fare | 運賃 |
| Cabin | キャビン番号 |
| Embarked | どこで乗船したか(C = Cherbourg, Q = Queenstown, S = Southampton) |
Summary
提供されているデータセットについての概要です。ここでは、3つのcsvファイル、計25カラムからなるデータが提供されていることがわかります。
Notebooks
他の参加者が公開したNotebookを参照することができます。
Discussion
ここでは、参加者同士がコンペに関して意見交換したり、質問をしたりします。コンペなので、モデル構築に関してあまり踏み込んだトークなどはできませんが、初心者のうちはわからないことも多いので、ここで先輩カグラーの皆さんに質問できるのはかなりありがたいと思います。ちなみに、英語力はそこまでなくても大丈夫です!!
Leaderboard
提出済みの課題の、ラインキングです。自分のランキングも確認できるので、スコア上げのモチベーションになります。
Rules
コンペのルールが記載されています。コンペ参加者はこのルールに従ってモデルの構築、データセットの取り扱い、課題の提出を行います。タイタニックのコンペでは、参加者1人ごとに1アカウントが必要であること、チーム外でのプライベート共有が不可であること、課題の提出は1日10回までであることなど、いくつかのルールが記載されています。また、常時開催のコンペであるため、課題の期限は”None”となっています。
Team
Kaggleのコンペには個人で挑戦することも可能ですが、チームでも参加できます。このタブではチームの管理ができます。
Submit
課題の提出についてはこの後詳しくみていきますが、過去に自分が提出した課題の履歴を確認する画面「My Submissions」と、課題提出を行う画面「Submit Predictions」があります。
Notebook:Notebookをつくろう
Notebook(旧称Karnel)とは
Kaggleには「Notebook」という、PythonやRなどの言語で機械学習を行う際によく使われる、Jupyter Notebookの実行環境が用意されています。通常、機械学習を始める際は、自身のコンピュータにモデル構築に必要なパッケージ類をインストールし、環境を構築する手間がかかりますが、Notebookを使うことで環境構築の手順を省略できます。さらに、月当たりの上限はあるものの、GPUやTPUを無料で使用することもできます。終了したコンペでは、他の参加者のNotebookが公開されていることも多く、初心者が学習を進めるのにも役立ちます。
タイタニックのコンペティションは、賞金のない常時開催型のコンペで、チュートリアルとして参加する人も多いことから、チュートリアルに役立つNotebookがいくつか公開されています。コンペのOverviewタブのDescriptionにも、Kaggle公式のGet Started 動画が用意されています。
今回は、Kaggle公式が公開しているNotebookに沿って進めていこうと思います。
Notebookの作成方法
Notebookの作成方法には大きく2つあります。
① + New Notebook
Notebookタブで新規Notebookを作成することができます。使用する言語(PythonまたはR)、タイプ(NotebookまたはScript)、高度な設定(Google Cloudサービスとの接続やプロセッサ)などを選択することができます。現在利用できるPythonのバージョンは3.6系のようです(2020年9月現在)。
+ New Notebookから新規Notebookを作成できます
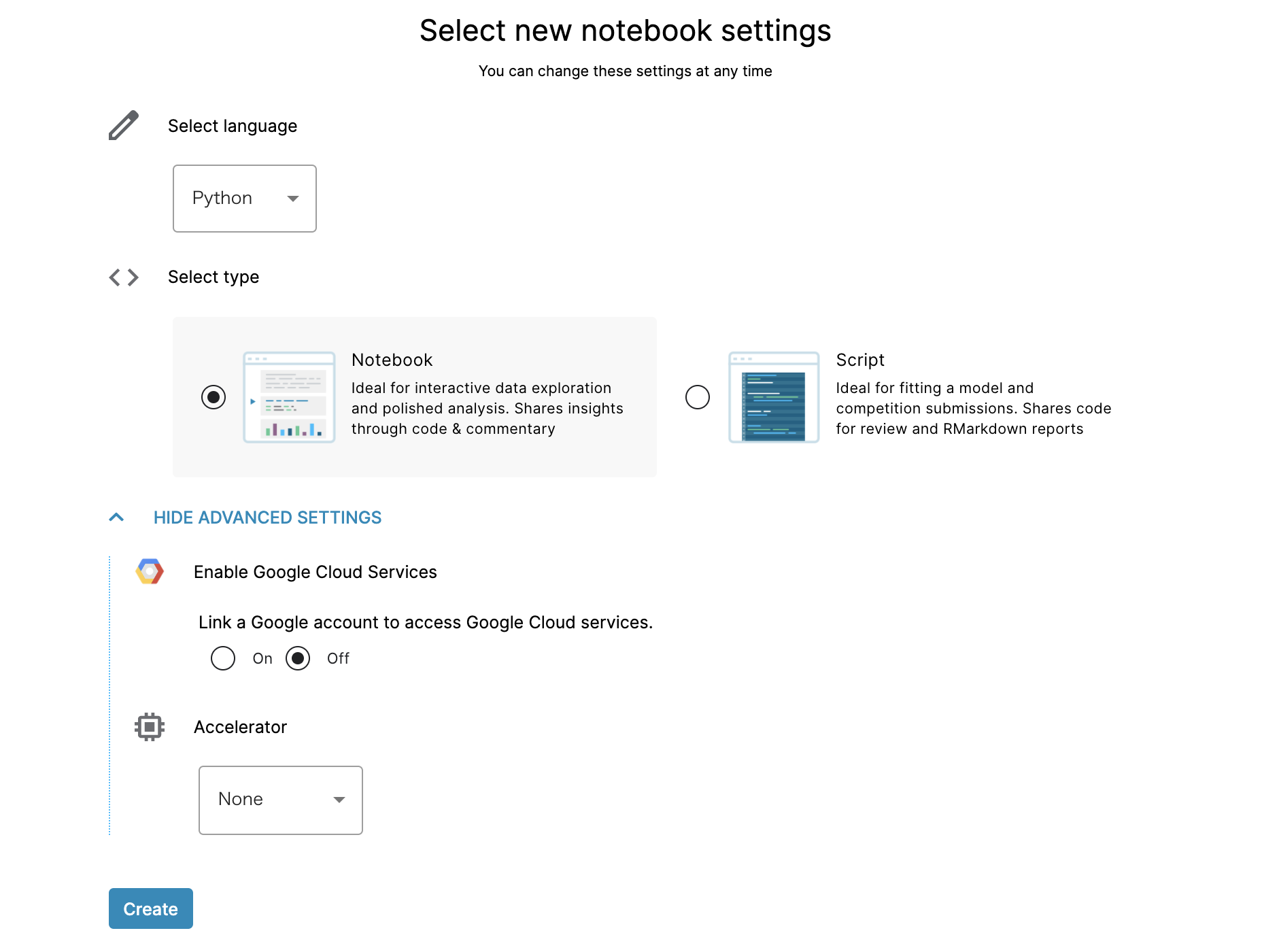
使用する言語、Notebookのタイプなどを選択することができます
通常は、各コンペページより”Notebooks” -> “New Notebook”として、そのコンペで提供されているデータセットを含んだ状態で新規Notebookを作成することがほとんどです。この場合は、当該コンペに参加するものとして、コンペの規約・ルールに同意する必要があります。
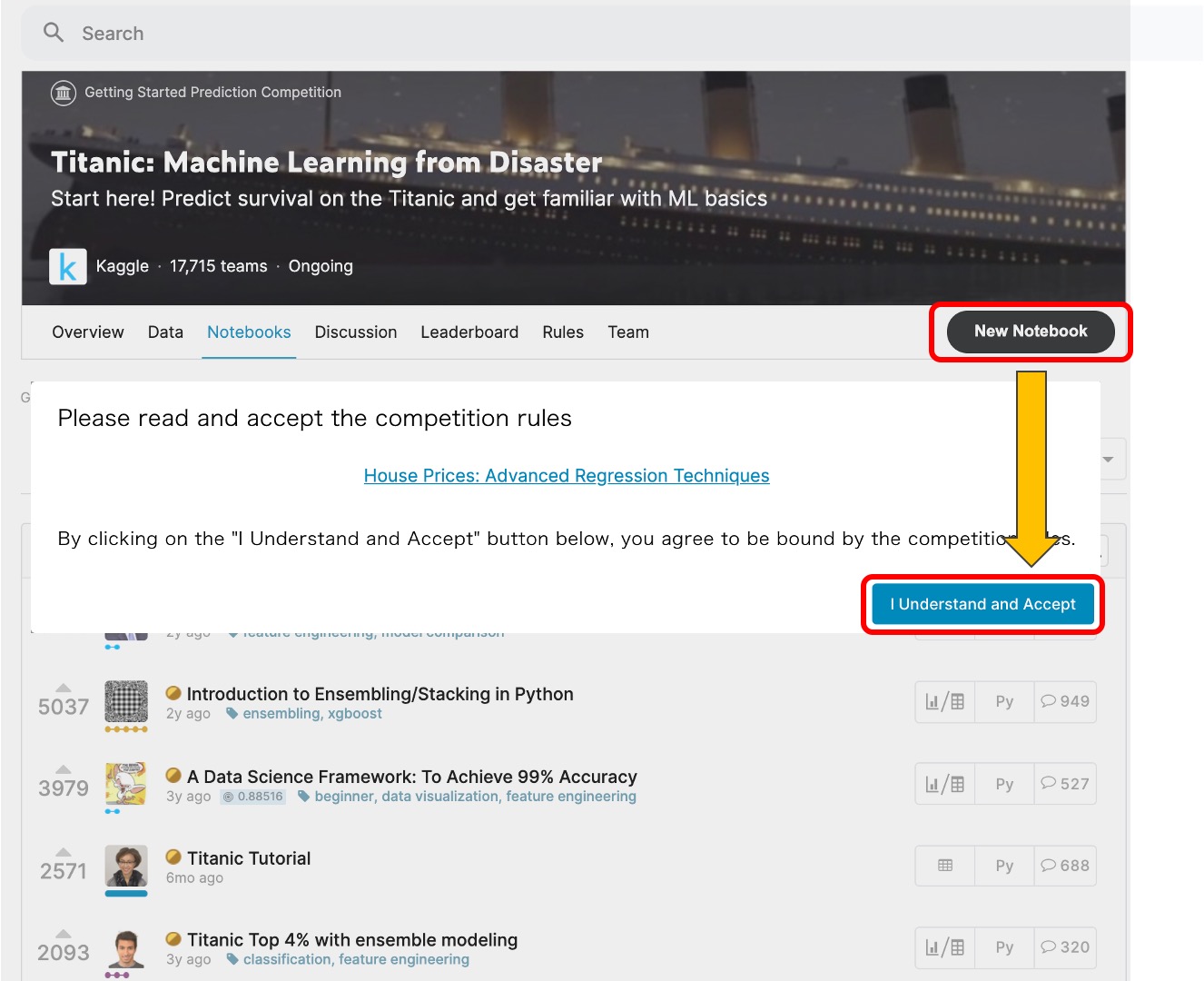
コンペ画面から新規作成すると、各コンペで公開されたデータセットが含まれた状態でNotebookが起動します
② Copy and Edit
既存のNotebookをコピーして使用することもできます。興味のあるコンペ画面のNotebooksタブから、対象のNotebookをコピーして編集します。今回は、先ほど紹介したKaggle公式から公開されているNotebookをコピーして、タイタニックの課題を進めていきます。
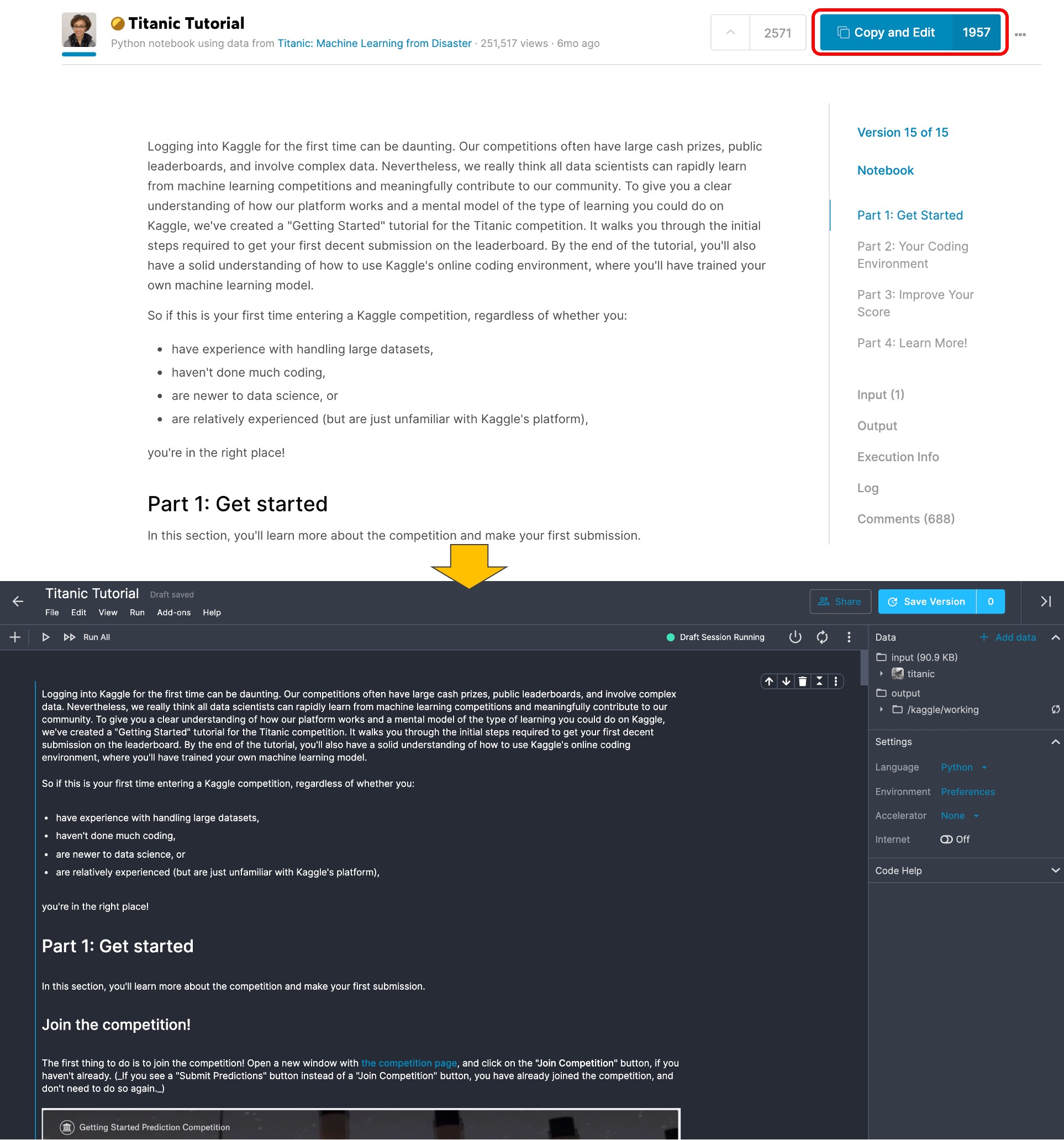
作成したNotebookは、Jupyter Notebookとほぼ同様の機能をもっています。画面中央に配置されたセルには自由に[+Code]または[+Markdown]を追加・削除し、実行することができます。また、画面右側では、SessionやDataの管理が可能です。各コンペの画面からNotebookを作成した際は、Inputディレクトリに使用するデータセットがデフォルトで含まれています(赤枠)。
Submit:課題を提出して順位表に載ろう
Step1:ベンチマークcsvを提出する
それでは実際に、タイタニックコンペに挑戦していきましょう。Kaggleの醍醐味は特徴量エンジニアリングや機械学習のモデル構築かと思いますが、まずは、submit(提出)してランキングに載って「おお〜!!」という高揚感を味わいましょう。
Kaggleで予測結果を提出するには、以下のような方法があります。(コンペによって若干違う場合もあり)
- Notebookから提出する
- csvファイルを直接アップロードする
- APIを使って提出する
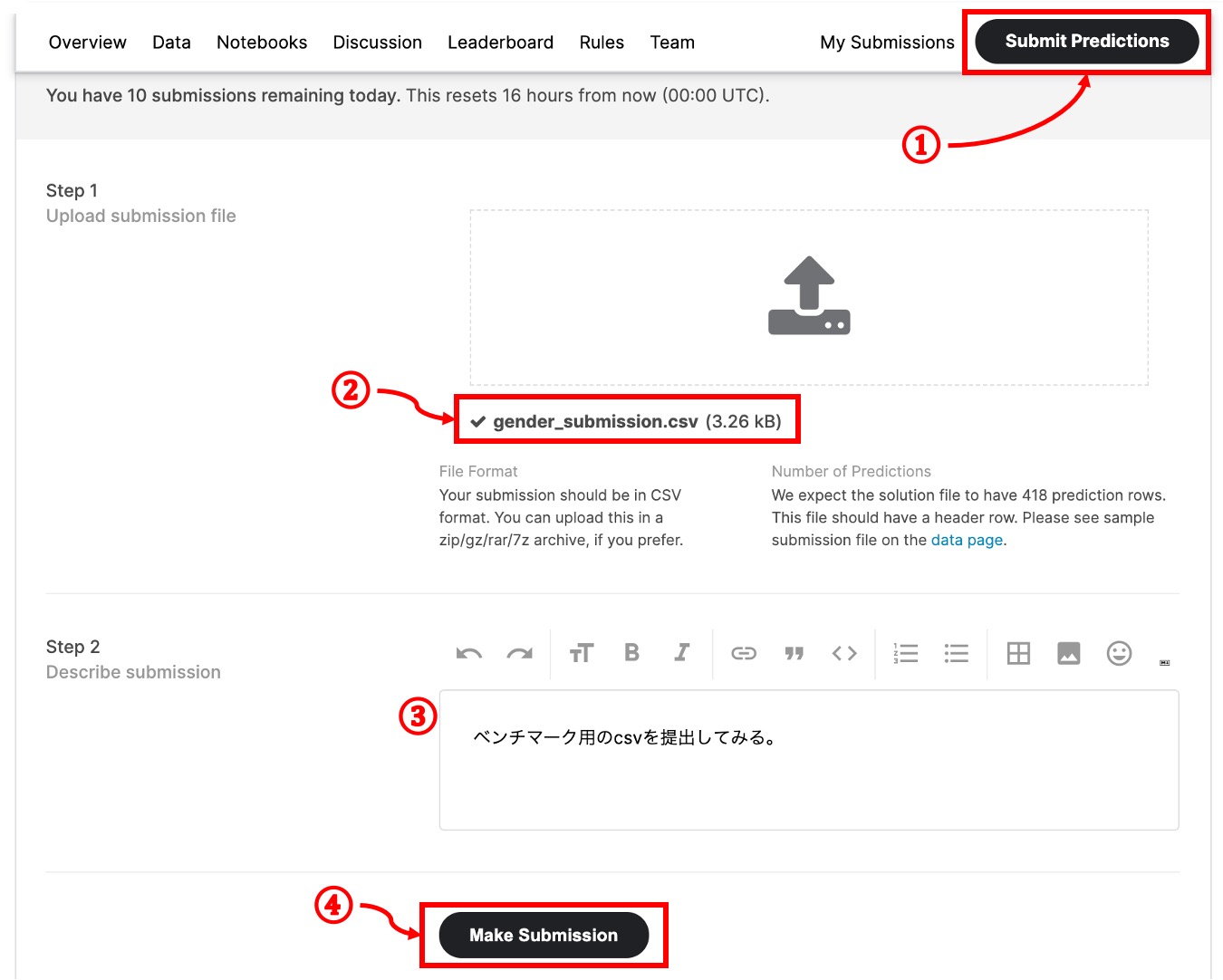
まずは、ベンチマークとしてデータセットとして提供されている「gender_submission.csv」を提出してみます。このcsvは性別が女性の場合”Survived = 1(生存)”とした、提出用csvと同じフォーマットのファイルです。このファイルをコンペページのDataタブからダウンロードしてローカルに保存します。

ダウンロードしたcsvファイルを、同じくコンペページの「Submit Predictions」ボタンからアップロードします。ファイルをドラッグ&ドロップもしくは選択し、提出用メモを記入して、「Make Submission」ボタンをクリックするだけで提出は完了です。
見事ランキングに載ることができました。順位は非常に低いですが、とりあえず予測結果を提出するまではできるようになりました。では次に、提供されたデータセットから学習したオリジナルの予測結果を提出してみましょう。
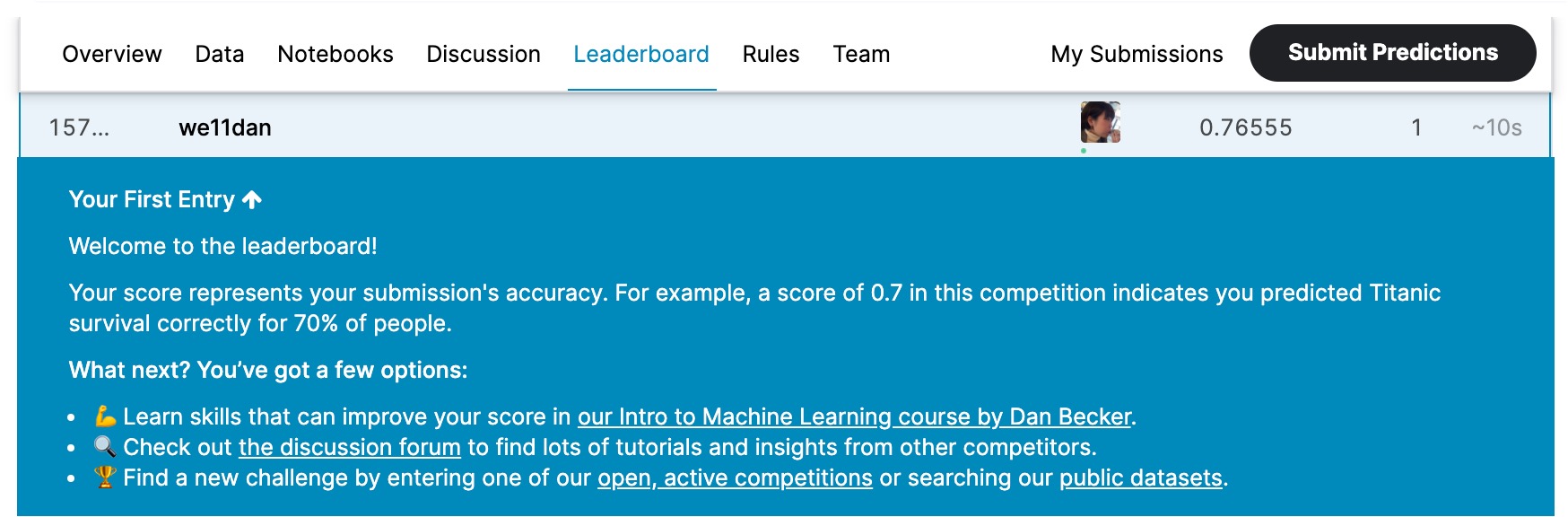
無事、Leaderboardにのりました
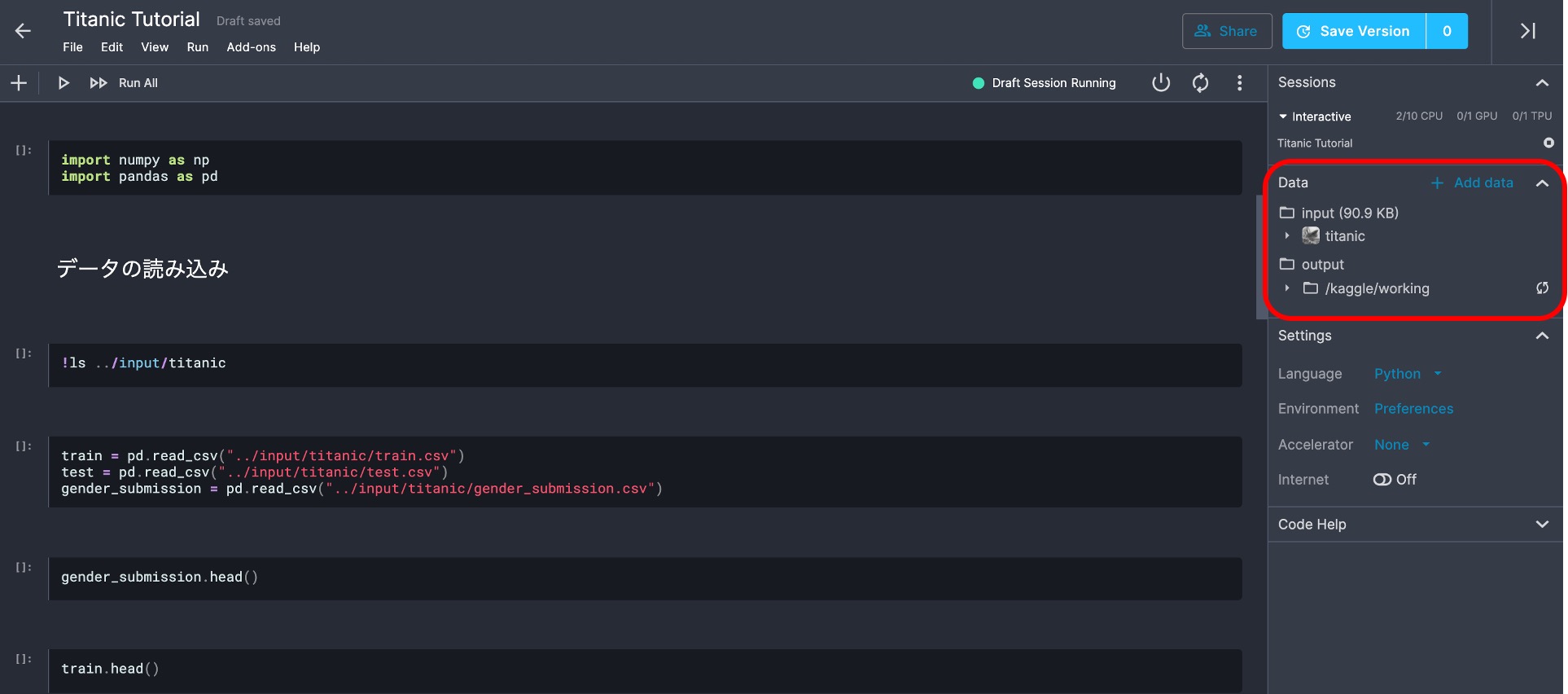
Step2:データを読み込む
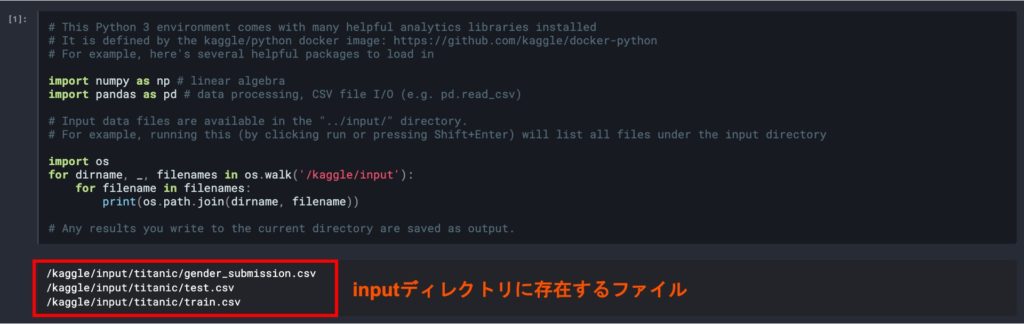
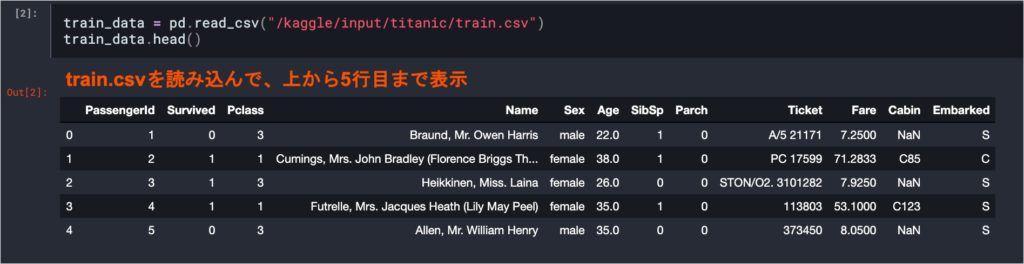
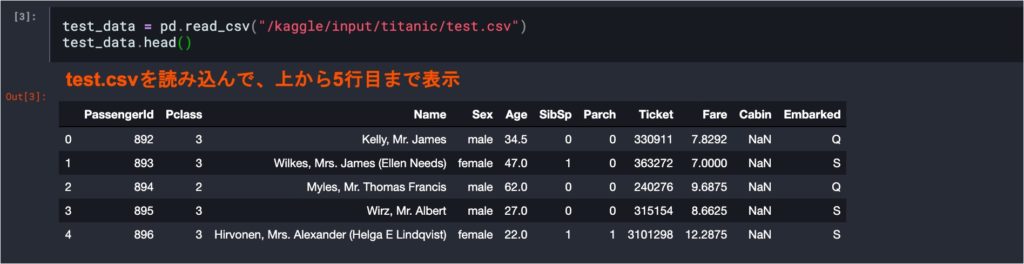
先ほどコピーしたチュートリアルのNotebookには、基本のコードが書かれているので、順番に実行していきます。始めに必要なライブラリのimportとファイルの読み込みを行ないます。以下では、train.csvとtest.csvをpandasのread_csv()関数を利用してDataFrameとして読み込んでいます。データを表示してみると、test.csvには「Survived」列が存在しないことがわかります。
Step3:データの特徴をつかむ
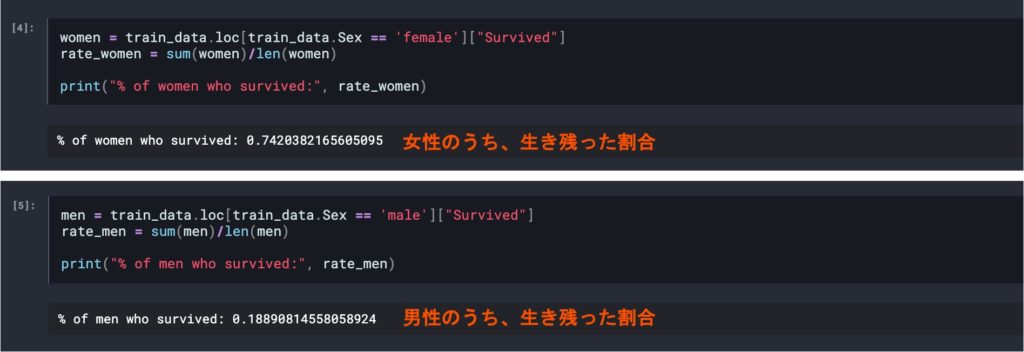
次に、今回データの特徴を学習するため、train.csvの「Sex(性別)」列に注目してみます。以下では、学習データから性別が女性である場合と男性である場合の「Survived」列をそれぞれ取り出し、生き残った割合を計算しています。女性が生き残る確率は約74%、男性が生き残る確率は約19%と、性別が生存に大きく寄与する要因であることが予想されます。同様にして、データの特徴を確認していくことができます。
Step4:機械学習モデルを作る
データの特徴がなんとなくわかってきたところで、いざ、機械学習モデルを作成してみましょう。
機械学習の基本的なモデルには「ロジスティック回帰」、「SVM」、「決定木」などさまざまありますが、今回は、決定木にアンサンブル学習採用した「ランダムフォレスト」というモデルを使用します。このモデルでは、学習データから一部のデータを取り出し、そのデータを各決定木で検証し、それぞれの予測した結果から、多数決で最終的な結果を判断します。

以下のコードでは、パターン検索を効率よく行うため、データのうち学習に使用する列を生存に関係しそうな「Pclass(チケットの等級)」、「Sex(性別)」、「SibSp(同乗の兄弟・配偶者の人数)」、「Parch(同乗の親・子供の数)」のみに絞っています。項目の成形は特に行なっておらず、かなり単純な処理ですが、このように予測結果に寄与しそうな項目を選択したり、ある項目の値を他の項目と関連づけて意味のあるデータとしたりすることは機械学習を行う際に非常に重要な作業となります。
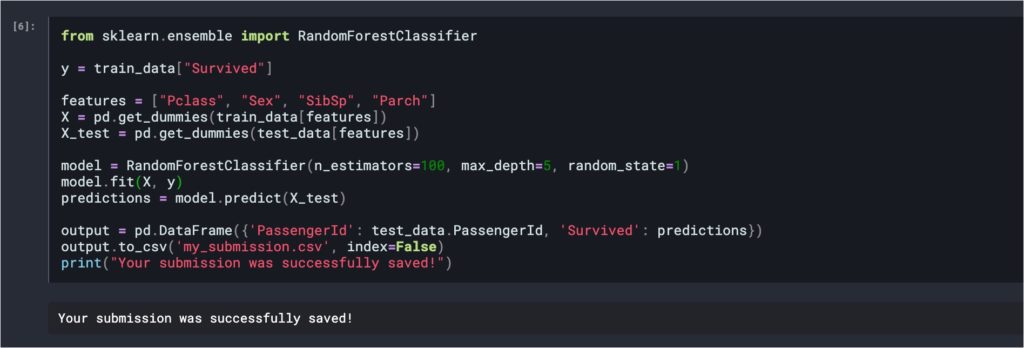
モデルの構築はたったの1行です。scikit-learnという機械学習のライブラリを使用して、100個の決定木(n_estimators=100)からアンサンブル学習を行なっています。このとき、決定木の深さ(max_depth)は5とし、random_state = 1と乱数を固定しています。
model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1)
モデル学習は.fit()メソッドで行います。ここでは予め学習用データから「Survived」列のみを抜き出した回答データ「y」、「Pclass、Sex、SibSp、Parch」列のみを抜き出した「X」を使って学習を行います。
model.fit(X, y)
学習済みのモデルを使って、生存かどうかを予測します。ここでは学習用データと同様に一部項目を抽出したテストデータ「X_test」を使用します。
predictions = model.predict(X_test)
最後に、予測結果をcsvに出力して処理は完了です。
Step5:オリジナル予測結果を提出する
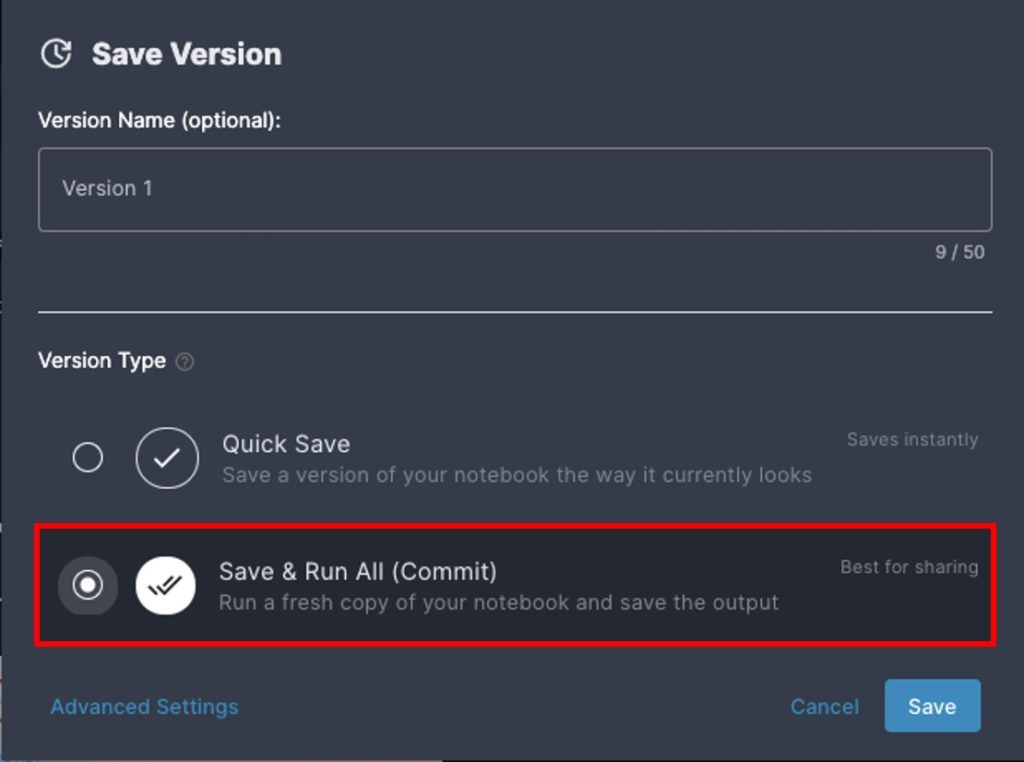
出力した予測結果のcsvを、提出します。まず、ここまで編集したNotebookを保存します。保存時のオプションは「Save & Run All(Commit)」を選択します。
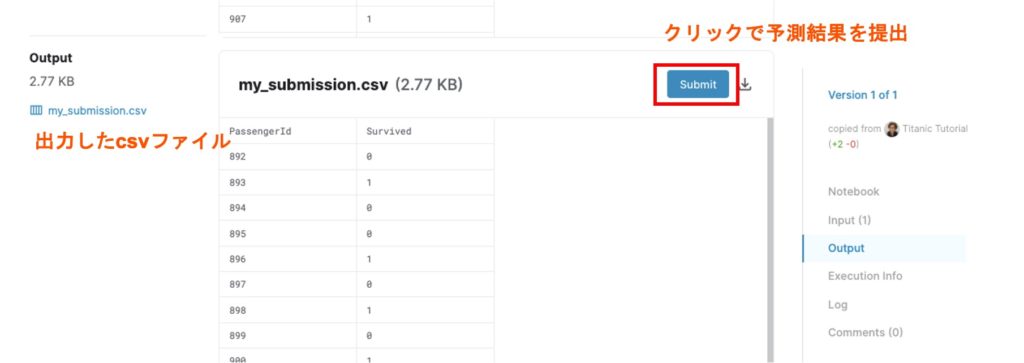
保存が完了したら、編集画面を終了し、”Notebook” -> “Output”から「Submit」ボタンをクリックして出力した予測結果を提出することができます。
以上で、初めてのKaggleコンペ挑戦は完了です。実際は、もっとモダンなモデルを選択したり、特徴量エンジニアリング、ハイパーパラメータ調整、交差検証など、スコアを上げるためにまだまだやることはたくさんありますので、引き続きいろいろと勉強していこうと思います。